Introduction à Prisma, un ORM novateur
Depuis quelques années, on entends de plus en plus parler dans le monde du JS serveur d'"ORM", ces bibliothèques qui permettent de gérer des base de données comme des ensembles d'entités.
On les a d'abord connu dans les années 2000 avec des langages comme PHP (on peut notamment penser à Doctrine, l'une des briques actuelles de Symfony), mais elles se sont petit à petit glissées dans l'écosystème Node.js jusqu'à arriver à un stade de maturité suffisant pour une utilisation en production.
Prisma, c'est quoi ?
Prisma est un ORM, une bibliothèque permettant de gérer une BDD de manière grandement simplifiée en représentant les tables sous forme d'entités. Comme nous allons le voir, il est loin d'être le premier à proposer cette approche, mais il apporte un certain nombre d'innovations qui le démarquent des autres bibliothèques du même genre.
Pourquoi utiliser un ORM ?
Il existe essentiellement trois approches majeures à la gestion d'une BDD côté serveur :
Soit on exécute des requêtes brutes, écrites à la main en SQL, ce qui permets d'avoir le maximum de flexibilité au détriment de la maintenabilité et de la sécurité (particulièrement si vous n'avez pas de système d'échappement automatique, ce qui crée un fort risque d'injections SQL).
Soit on construit des requêtes étape par étape à l'aide d'un query builder, qui va fournir des aides (helpers) pour produire une requête complète et sécurisée, qui sera ensuite traduire en SQL et exécutée sur le serveur.
Ces deux approches sont très courantes mais posent plusieurs problèmes majeurs : tout d'abord, c'est verbeux. Ensuite, non typé. Cela signifie que si vous modifiez le schéma de votre BDD, les requêtes que vous écrivez risquent d'échouer, d'avoir des résultats inattendus ou de vous renvoyer des données invalides. Mais vous ne le découvrirez qu'au moment de l'exécution, et seulement après de potentiellement longues sessions de debug.
Il s'agit d'une perte de temps et potentiellement de données, pouvant aller jusqu'à la corruption. C'est là qu'interviennent alors les ORM.
Un ORM permets de reproduire le schéma de votre BDD en local pour vous simplifier la vie en structurant tant les données soumises au serveur que celles qu'il renvoie. En typant les données d'un bout à l'autre, on évite la majorité des écueils possibles avec les deux approches précédentes. D'autre part, le système d'entités permets souvent de représenter des relations, simplifiant grandement la gestion des jointures.
Certains ORM proposent également de générer leurs entités à partir d'une BDD existante, ce qui permets d'avoir un typage complet du début à la fin.
Petit tour d'horizon des ORM existants
Dans l'écosystème Node.js (ou Denon / Bun), il existe un certain nombre d'ORM dont les évolutions se basent sur les problèmes trouvés dans leurs prédécesseurs.
L'un des ORM les plus utilisés est Sequelize, qui est typé dynamique : on écrit typiquement le schéma à la main en utilisant les utilitaires fournis par la bibliothèque pour le valider contre celui de la base de données.
L'un des ses gros problèmes est le manque de typage : c'est une bibliothèque JavaScript avant tout. Elle s'est certes adaptée pour évoluer à l'arrivée de TypeScript, mais ce support reste très peu intégré au reste du système.
Arrive alors TypeORM, qui comme son nom l'indique est conçu pour une utilisation principalement en TypeScript : tout est toujours manuel mais par défaut les déclarations permettent d'obtenir de vrais types que l'on peut ensuite utiliser dans son application.
TypeORM est encore aujourd'hui très utilisé en production, ayant fait ses preuves comme un ORM robuste et fiable.
Malgré cela, plusieurs problèmes sont apparus au fil des ans : tout d'abord la DX (Developer Experience) dont les standards ont évolué depuis, le fait qu'un seul mainteneur s'occupait de la majorité du travail, pénalisant considérablement les avancées technologiques de la bibliothèque, etc.
Vient ensuite Mikro ORM. Un ORM moderne, robuste, conçu en prenant en compte les erreurs et/ou problèmes apparus dans TypeORM et dans les autres bibliothèques. Utilisant plusieurs principes novateurs pour l'écosystème tels que les Unit of Work, il se hisse rapidement comme une référence permettant d'obtenir d'excellentes performances tout en ayant un typage très propre.
L'arrivée de Prisma
Là où tous les ORM que nous avons cité utilisent des déclarations JS / TS pour le schéma (code-first), Prisma est à contre-courant : il utilise le principe dit du schema-first.
Pour faire simple, vous créez un fichier main.prisma dans votre projet, avec par exemple le contenu suivant :
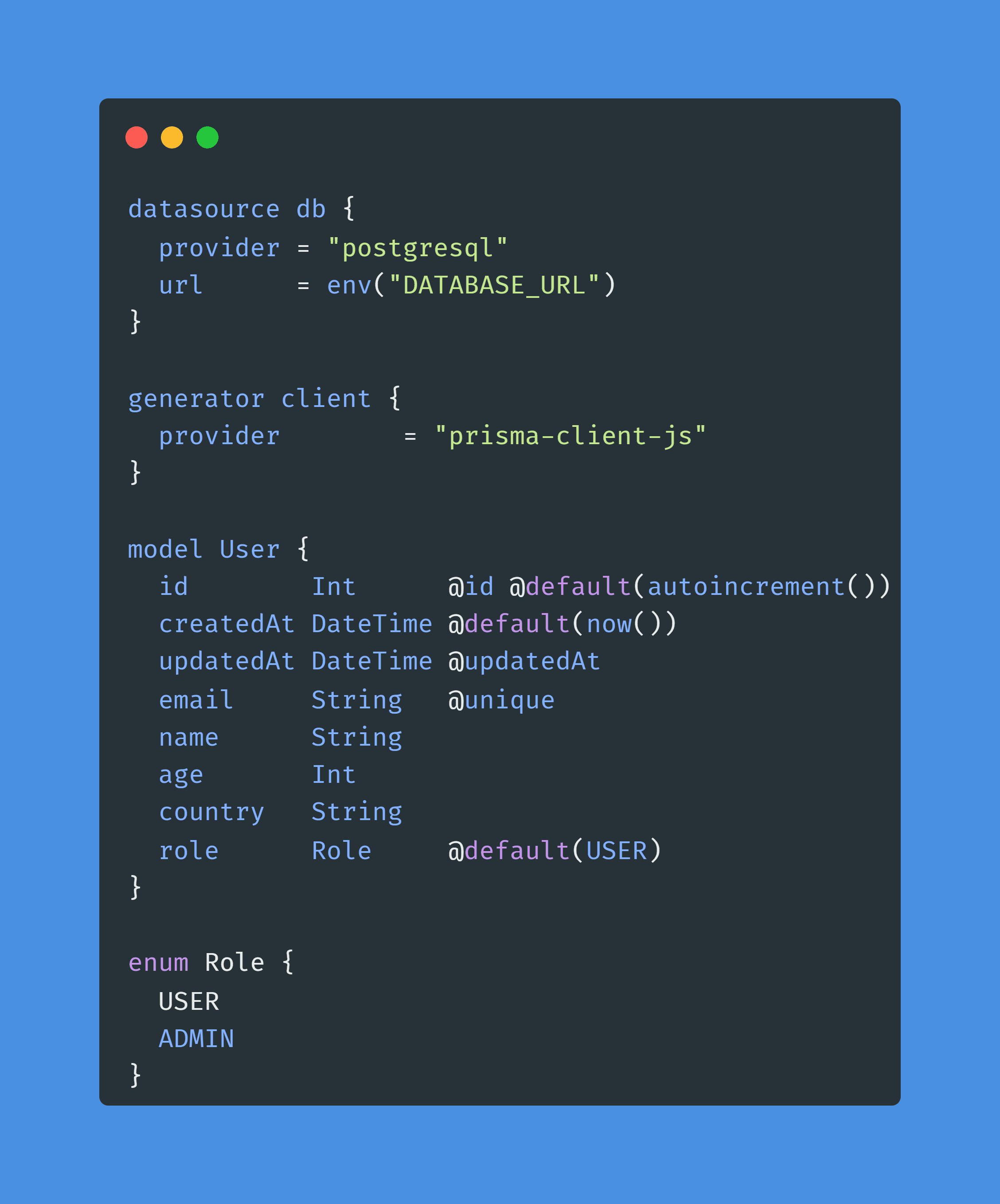
Comme vous pouvez le voir, c'est un format simple et épuré, conçu pour être le plus intuitif possible. La fonction env() permets d'aller récupérer une variable d'environnement au runtime.
Pour les relations, on peut faire comme suit :
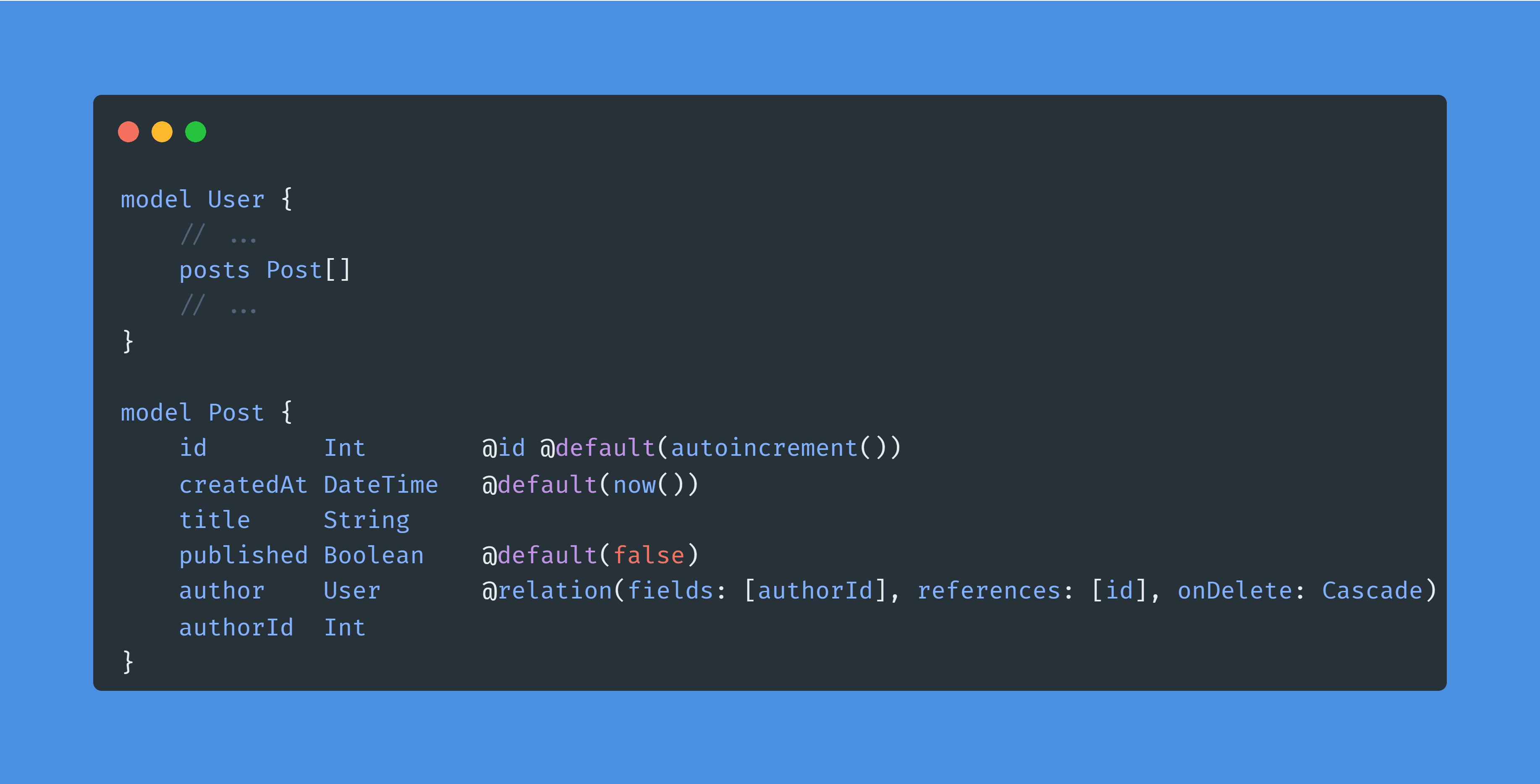
Les relations sont ce qu'on appelle des first-class citizens, ce qui signifie qu'elles sont supportées directement par Prisma, sans avoir de 'hack' à utiliser.
Une fois votre schéma en main, vous pouvez le générer avec l'outil en ligne de commande de Prisma inclut dans le runtime (préalablement installé via npm i prisma): prisma generate.
Prisma génère alors un dossier contenant des fichiers TypeScript contenant tous les types de votre base de données. Ensuite, il n'y a plus qu'à les utiliser !
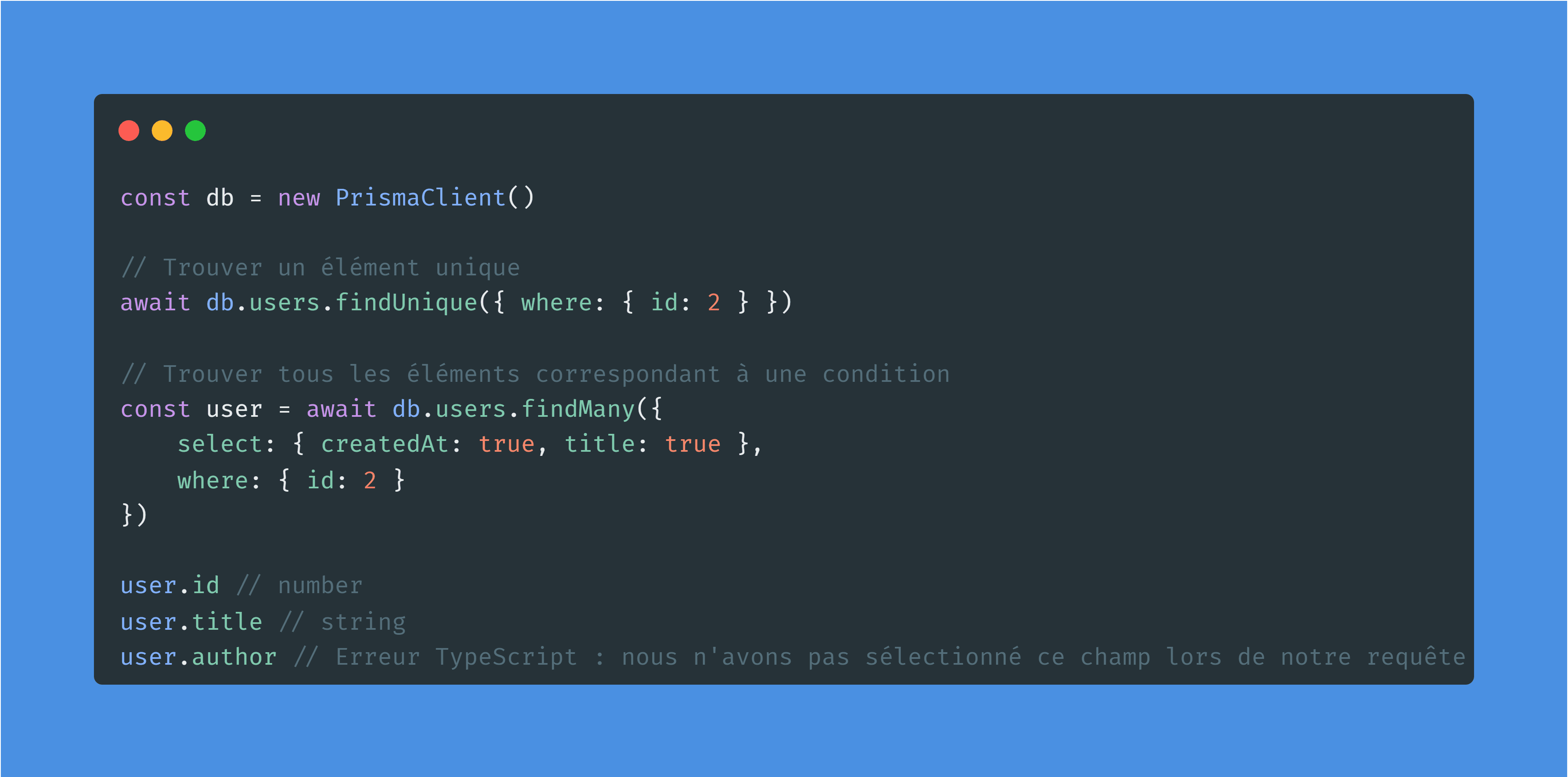
Comme vous pouvez le voir avec ce dernier exemple, les types de Prisma sont dynamiques : ils s'ajustent automatiquement en fonction de ce que vous essayez de faire.
Ici, si l'on demande à l'ORM de ne sélectionner que deux des colonnes, le type de retour ne contiendra que ces deux-là, pas les autres. Cela permets d'éviter énormément d'erreur de gagner beaucoup de temps à l'autocomplétion de l'IDE.
Les jointures sont supportées de la même manière :
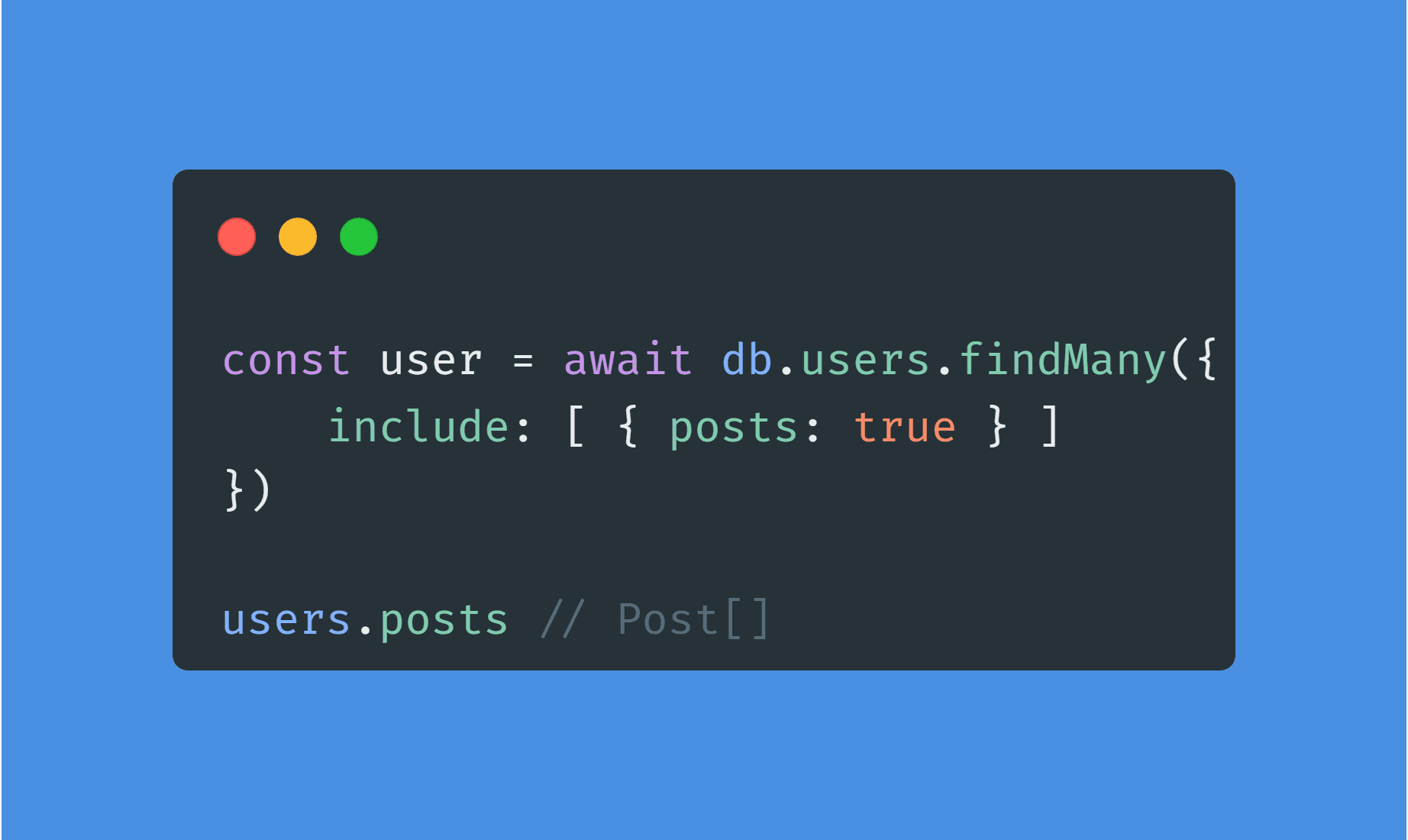
La jointure sera automatiquement réalisée sans que vous n'ayiez rien à faire d'autre.
Il faut également noter que Prisma est doté d'un système de migrations automatique : vous pouvez lui faire comparer votre schéma à celui de votre base de données, et générer une migration (up/down) en fonction du résultat, automatiquement.
Si vous maintenez déjà votre base de données autrement et ne souhaitez pas écrire un schéma Prisma directement, sachez qu'il est également possible de générer un schéma à partir d'une base de données existantes. Nous avons pu essayer ce système dans plusieurs projets et le résultat a toujours été très concluant. On obtient alors directement tous les avantages des types dynamiques de Prisma tout en n'ayant rien à écrire en terme de schéma, puisque notre BDD est la source de vérité.
Prisma, l'ORM ultime ?
Après plus d'un an à utiliser Prisma intensivement sur plusieurs projets, on ne peut que saluer la robustesse et l'intuitivité de cette bibliothèque qui va loin au-devant de ce que permettent TypeORM ou Mikro ORM pour ne citer qu'eux.
En revanche, il faut garder à l'esprit que ce n'est pas la solution parfaite pour tout le monde. En effet, Prisma nécessite de générer du code dans tous les cas - cela peut être un problème pour certains workflows. Les types générés sont nombreux, ce qui peut causer des problèmes de performances pour les base de données très complexes.
D'autre part, les performances ne sont pas encore optimales. Bien qu'il y ait eu de grandes améliorations durant les derniers mois, si l'on compare à des requêtes faites et optimisées à la main, certains cas d'usage ne sont pas aussi rapide avec Prisma.
En revanche, c'est assurémment un ORM solide, robuste, bien assez mature pour être utilisé en production, et qui pourra être un atout majeur dans l'utilisation d'une base de données notamment relationnelle (MySQL, MariaDB, PostgreSQL, etc.)
Quelles alternatives ?
À noter que de nouvelles bibliothèques font petit à petit leur apparition avec leurs propres nouveautés ; trop jeunes pour être utilisé sans crainte en production, elles ont le mérité de proposer des choses nouvelles qui pourraient très bien être de nouvelles références dans un futur proche.
Je pense notamment à Drizzle, un ORM dont le fonctionnemment fait penser à celui de Prisma mais souvent plus léger ; ou bien à Kysely, qui n'est rien de plus qu'un query builder mais entièrement typé, générant à la volée les types dont vous avez besoin en fonction du schéma BDD fourni et des saisies effectuées.
Il reste encore de nombreuses choses à explorer, mais Prisma se positionne comme l'un des acteurs majeurs actuels en terme d'ORM, avec un fonctionnement innovant qui a démontré son intérêt au fil des missions que nous avons pu effectuer avec. Même s'il n'est pas parfait, ses qualités suffisent largement pour surpasser dans un certain nombre de cas les alternatives actuellement disponibles telles que TypeORM ou Mikro ORM.



