Nhost, le Backend-as-a-Service open source qui nous a convaincus
Nhost, c’est quoi ?
Nhost est un backend-as-a-service (Baas) open source qui permet de réaliser un back-end rapidement et facilement pour des applications web et mobile moderne. Nhost va permettre au développeur de construire son application en s’affranchissant des aspects techniques back-end, complexe et chronophage, pour se concentrer sur son produit.
Nhost a pour ambition d’être pour le back-end ce que Netlify et Vercel sont pour le frontend.
💡 Backend-as-a-Service (BaaS) est un modèle de service cloud dans lequel les développeurs externalisent tout l’applicatif backend.
Pourquoi utiliser ce type de solutions ?
Démarrer un nouveau projet prend du temps
En effet, après avoir choisi la stack technique d’un projet, un développeur va devoir démarrer plusieurs gros chantiers back-end avant même de coder la première page de son application :
-
Le boot-strapping du serveur,
-
La création de la base de données,
-
La gestion du stockage sur le cloud,
-
L’authentification des utilisateurs,
-
L’hébergement,
-
Le déploiement automatique, etc.
L’externalisation de toutes ses tâches va permettre à l’utilisateur de gagner plusieurs jours/semaines de travail suivant la stack technique choisie.
Pourquoi ne pas avoir choisi d’utiliser un boiler plate maison ?
💡 Un boiler plate est une base de code générique et configurable que l’on réutilise à chaque démarrage de projet.
Le problème du boiler plate est que sa maintenance est très coûteuse. De plus, écrire un boiler plate est compliqué car il doit pouvoir s’adapter facilement à tous nos projets.
Pourquoi avoir choisi Nhost ?
Nhost est une alternative parmi une multitude de concurrents :
-
Google Firebase
-
AWS Amplify d’Amazon
-
Supabase
-
Appwrite
-
back4app
Alors pourquoi avoir choisi cette solution plutôt qu’une autre ? Voyons ensemble quelles sont les forces de Nhost.
Une solution open source
Nhost est open source à l’inverse des solutions proposées par Google et Amazon. Les responsables informatiques se tournent de plus en plus vers l’open source. En effet, l’open source rassure de par sa transparence : l’autorisation de consultation du code permet à chacun de faire une analyse et donc de détecter des problèmes de sécurité. Mais également car l’open source permet une amélioration de la qualité des logiciels car chacun peut contribuer.
Une base de données relationnelle
Nhost utilise une base de données relationnelle contrairement à Firebase et Appwrite. Nhost a fait le choix d’utiliser PostgreSQL. PostgreSQL est l’un des systèmes de gestion de base de données (SGBDR) les plus populaires, avec MySQL. Il est même considéré comme le SGBDR le plus fiable et le plus robuste (diversité des données, complexité des requêtes, grand volume de données…). Un des inconvénients de PostgreSQL est sa configuration, mais avec Nhost, tout ceci est totalement transparent pour l’utilisateur.
L’API GraphQL
L’un des gros avantages de Nhost par rapport à ses concurrents, c’est de pouvoir utiliser une API GraphQL. C’est la première chose que l’on voit quand on se rend sur le site nhost.io.
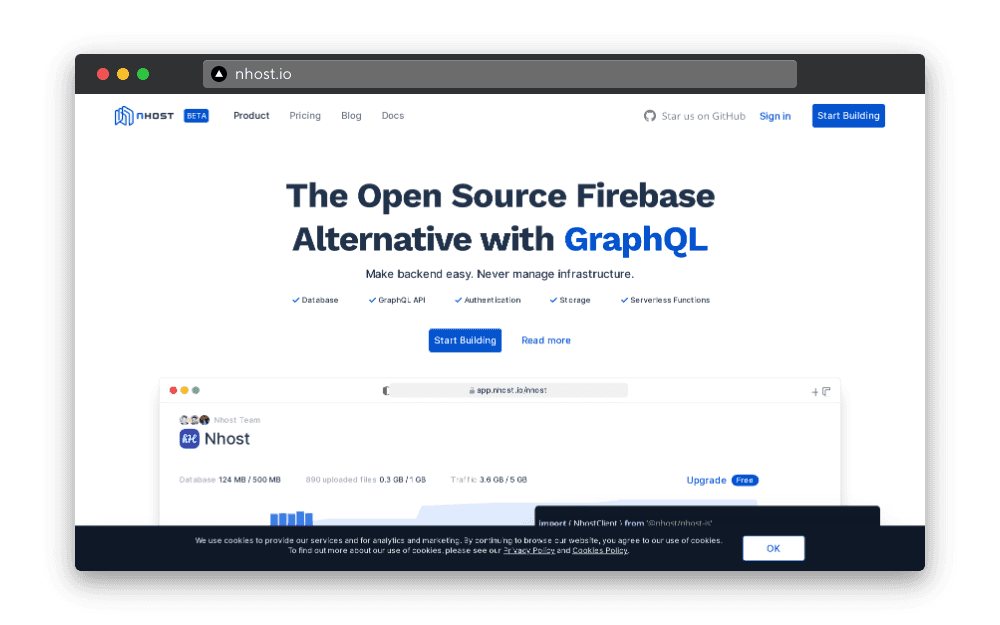
💡 GraphQL est un langage de requête développé par Facebook et qui permet à un frontend d’obtenir des données du back-end. C’est une alternative aux API REST.
GraphQL présente de nombreux avantages par rapport aux API REST :
-
Une seule requête par page pour obtenir toutes les informations nécessaires
-
Récupération uniquement des informations utiles
-
Un typage des données de la base de données jusqu’au frontend
-
Une exécution rapide
-
Temps réel grâce aux souscriptions (Web-socket)
-
Possibilité de générer automatiquement de la documentation…
Cette API permet donc de limiter le flux de données entre le frontend et le back-end, ce qui donne des applications qui s’exécutent rapidement et qui consomment une quantité de data limitée. GraphQL permet également de limiter les erreurs grâce au typage de bout en bout.
L’effort d’apprentissage de cette nouvelle méthode n’est pas nul mais reste très faible grâce à la documentation très claire et complète accessible ici.
Hasura, solution utilisée par Nhost pour l’API GraphQL
Nhost externalise les problématiques GraphQL en utilisant la plateforme Hasura. En effet, Hasura est une solution pour créer une API GraphQL (mais pas que) pour n’importe quelle base de données.
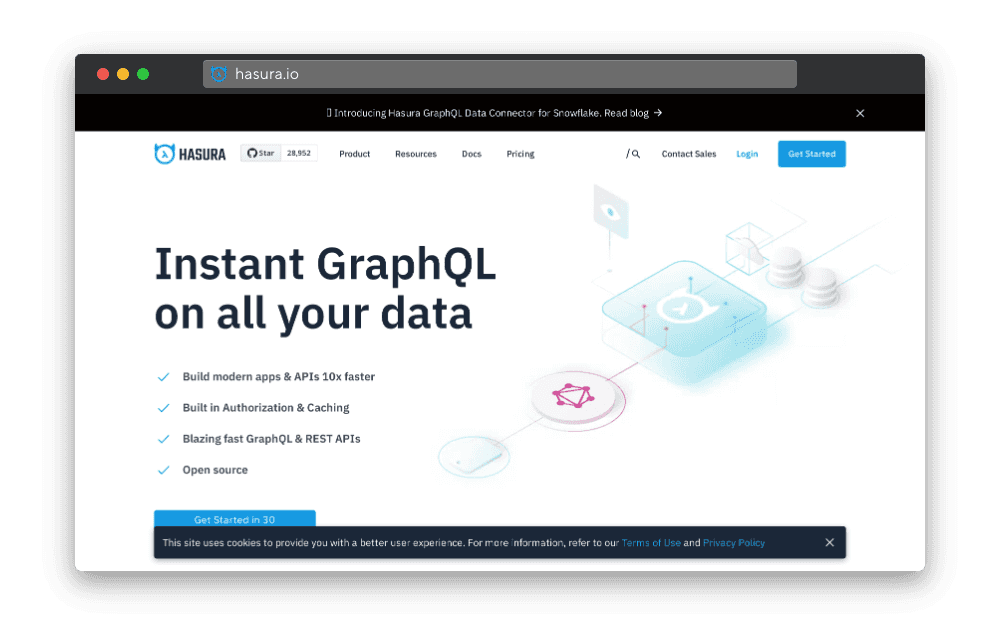
En plus de l’API GraphQL, Hasura offre de nombreuses fonctionnalités aux développeurs comme les événements déclenchés (events trigger), les computed fields, les CRONs, un exploreur GraphQL… Toutes les fonctionnalités sont à retrouver ici.
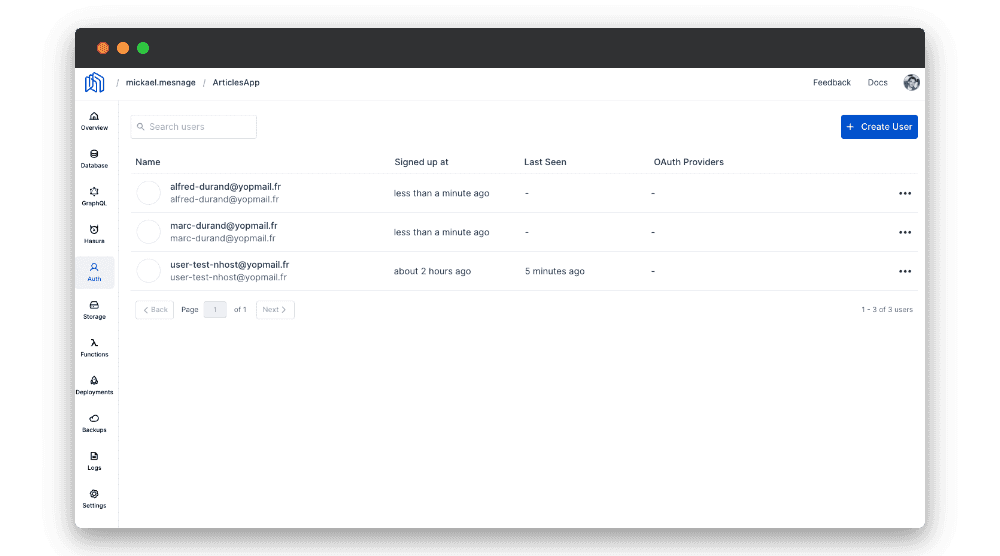
Authentification
Comme l’ensemble de ses concurrents du marché, Nhost dispose d’un service d’authentification clefs en main grâce à Hasura Auth. L’utilisateur pourra intégrer directement ce service dans son application.
Le service gère l’authentification classique via e-mail et mot de passe avec les fonctionnalités classiques d’inscription, de connexion, de déconnexion et de réinitialisation de mot de passe avec envoi de mails customisables. Le service gère également une multitude d’autres méthodes d’authentification moins classiques :
-
Lien magique
-
Numéro de téléphone
-
WebAuthn API
-
Apple
-
Discord
-
Facebook
-
Github
-
Google
-
Linkedin
-
Spotify
-
Twitch
Ce service permet également de définir et d’associer des rôles par utilisateur. Ces mêmes rôles pourront être utilisés par l’API GraphQL pour restreindre la portée de certaines données.
Une console d’admin est fournie pour que l’administrateur puisse accéder aux utilisateurs inscrits.
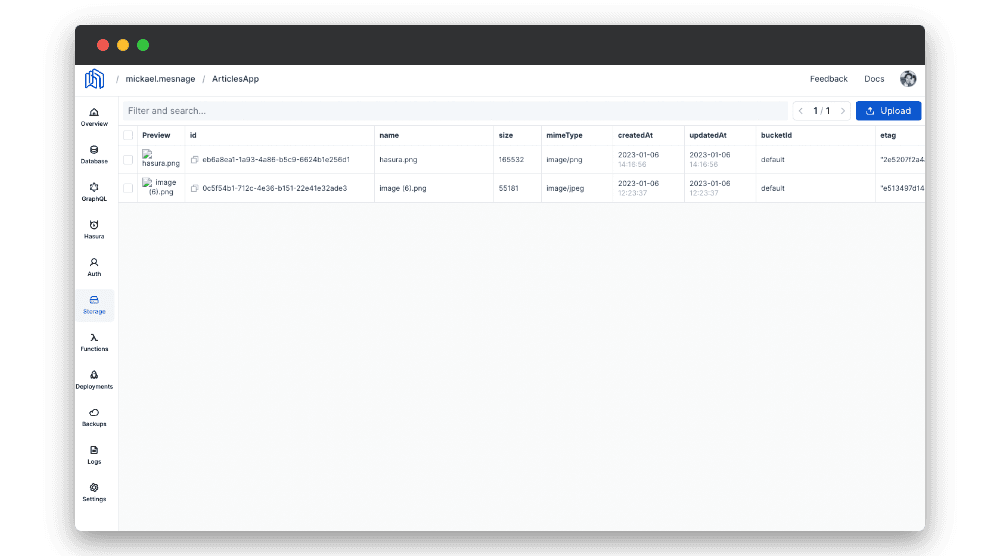
Stockage
Nhost fournit une solution de stockage (CDN S3) afin de permettre aux utilisateurs d’uploader et d’afficher des fichiers. Une console admin est également fournie pour que l’administrateur puisse accéder aux documents uploader.
Serverless fonctions
Avec une architecture sans backend, le développeur va devoir écrire presque l’intégralité du code coté frontend. Cependant, il est possible qu’il veuille écrire une partie du code coté backend pour diverses raisons :
-
Utilisation de token secret
-
Factorisation de code utilisé par plusieurs frontend
-
Vérification de données sensible après soumission d’un formulaire
-
Intégration d’une API externe…
Cela est possible grâce aux clouds fonctions. Il faudra pour cela initialiser un serveur express au sein du projet Nhost. Ensuite, le développeur pourra générer des endpoints HTTP.
Le schéma suivant résume l’architecture du backend avec l’ensemble des fonctionnalités décrites précédemment :
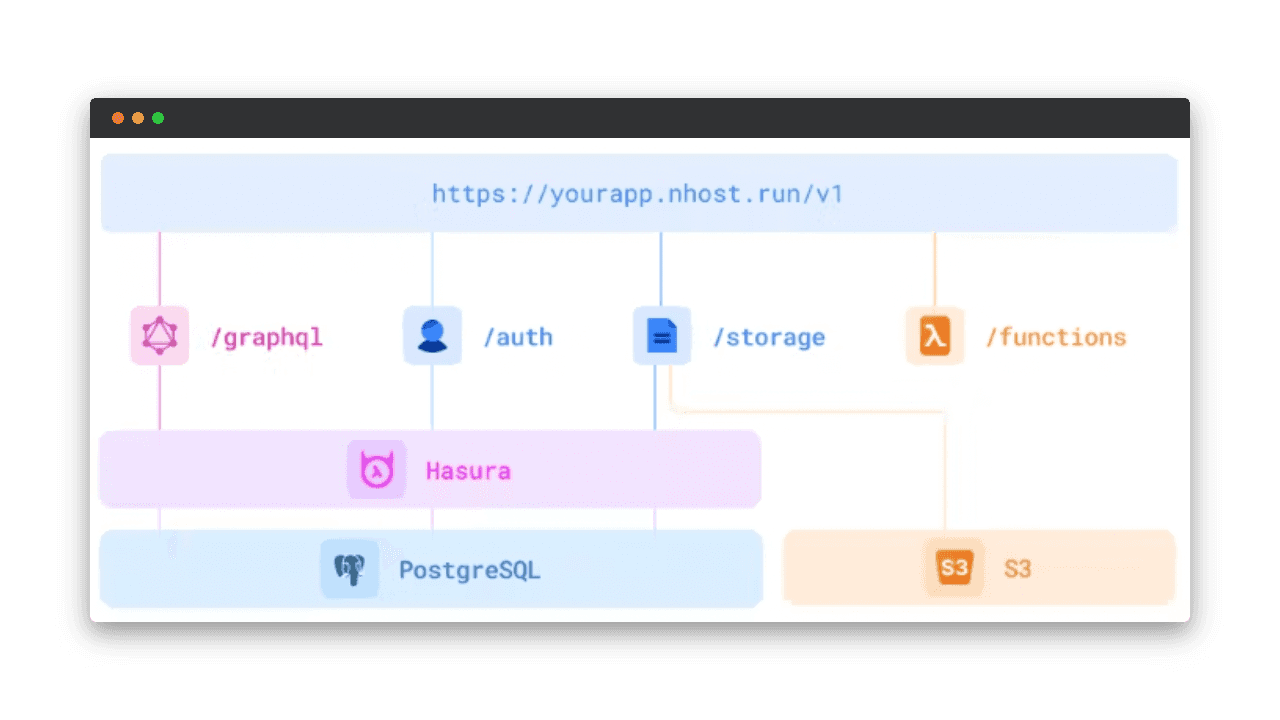
SDK
Il existe plusieurs SDK pour utiliser Nhost avec les frameworks frontend les plus populaires suivants :
-
ReactJS
-
Next.js
-
Vue
-
…
Ces SDK vont permettre aux développeurs d’utiliser facilement les fonctionnalités Nhost relatives à l’authentification, au stockage de fichier et aux clouds fonctions. Un SDQ javascript est également fourni.
CLI
Nhost fournit un CLI pour initialiser et lancer le projet en local. Grâce à lui, vous allez pouvoir développer et tester votre back-end en local sur votre machine.
Le frontend dans tout ça ?
Vous pouvez utiliser le framework que vous voulez. Comme vu plus haut, plusieurs SDK existent pour faciliter le travail du développeur.
Nhost fait beaucoup de choses, mais il ne gère pas l’hébergement du front. Il est conseillé d’utiliser Netlify ou Vercel qui est rapide à paramétrer pour, encore une fois, se concentrer sur le fonctionnel.
💡 Netlify et Vercel sont des services d’hébergement statique avec déploiement continu intégré.
Quelques exemples sur l’utilisation de Nhost avec le framework ReactJS
Il existe un tutoriel pour démarrer Nhost avec React ici.
Les exemples suivants sont tirés du projet suivant : https://github.com/MickaelMesnage/nhost_presentation
Le projet comporte 3 onglets :
-
Articles : permet à un utilisateur connecté de créer ses articles, de les visualiser (uniquement les siens) et d’ajouter des likes aux articles qu’il préfère.
-
Images : permet à un utilisateur connecté d’uploader ses images et de les visualiser (uniquement les siennes).
-
Récupérer un token : permet de récupérer un token.
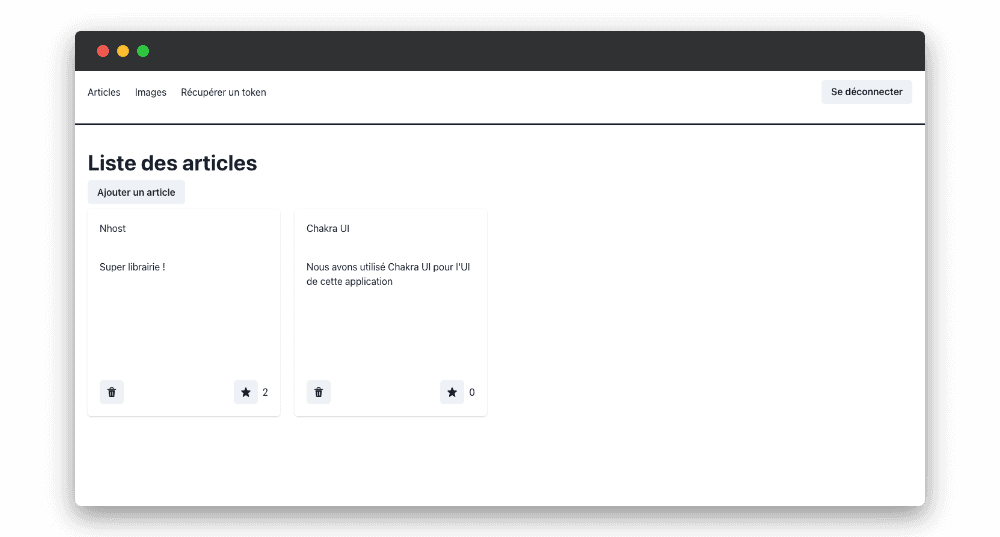
Le répertoire est composé d’une partie backend avec les fichiers Nhost et une partie frontend avec l’application ReactJS généré avec vite (typescript, chakra-ui, react_router_dom, Apollo client pour GraphQL, codegen pour la génération des hooks GraphQL…).
Vous trouverez plus d’informations dans le ReadME du projet. Le site est disponible ici.
Installation du CLI Nhost
Il faudra installer au préalable docker sur votre machine. Puis vous pourrez ensuite installer le CLI Nhost pour démarrer l’expérience. Plus d’informations ici.
Inscription et connexion de l’utilisateur
Le développement de la page d’inscription et de connexion est très rapide grâce au SDK fourni.
Pour utiliser le SDK, nous devons d’abord utiliser le provider de Nhost :
import { NhostReactProvider, NhostClient } from '@nhost/react';
import { NhostApolloProvider } from '@nhost/react-apollo';
import { BrowserRouter } from 'react-router-dom';
import Router from './router';
const nhost = new NhostClient({
subdomain: "localhost",
region: null,
});
const App = () => (
<NhostReactProvider nhost={nhost}>
<NhostApolloProvider nhost={nhost}>
<BrowserRouter>
<Router />
</BrowserRouter>
</NhostApolloProvider>
</NhostReactProvider>
);Il faut ensuite connecter les formulaires d’inscription et de connexion directement avec la méthode fournit par le SDK. Comme ici pour l’inscription :
import { useSignUpEmailPassword } from '@nhost/react';
// Hook provided by nhost sdk for react
const { signUpEmailPassword, isLoading } = useSignUpEmailPassword();
// Signup form submit callback
const onSubmit = async () => {
if (areEmailAndPasswordValid()) {
const { error } = await signUpEmailPassword(email, password);
if (error) {
toastError("Error lors de l'inscription !");
} else {
toastSuccess('Inscription réussie');
resetFields();
goToHome();
}
}
};Et là pour la connexion :
import { useSignInEmailPassword } from '@nhost/react';
// Hook provided by nhost sdk for react
const { signInEmailPassword, isLoading, needsEmailVerification } =
useSignInEmailPassword();
// Signin form submit callback
const onSubmit = async () => {
if (areEmailAndPasswordValid()) {
const { error } = await signInEmailPassword(email, password);
if (error) {
toastError("Erreur lors de la connexion !");
} else {
toastSuccess('Connexion réussie');
resetFields();
goToHome();
}
}
};On voit ici que pour la connexion, le SDK nous donne l’information si l’e-mail doit être vérifié lors de la première connexion. On peut désactiver cette fonctionnalité si nécessaire dans le fichier config.yaml de Nhost.
E-mail d’authentification
Comme on l’a vu précédemment, Nhost gère l’envoi des e-mails lors de l’inscription et la réinitialisation de mot de passe. On peut customiser les e-mails envoyés :
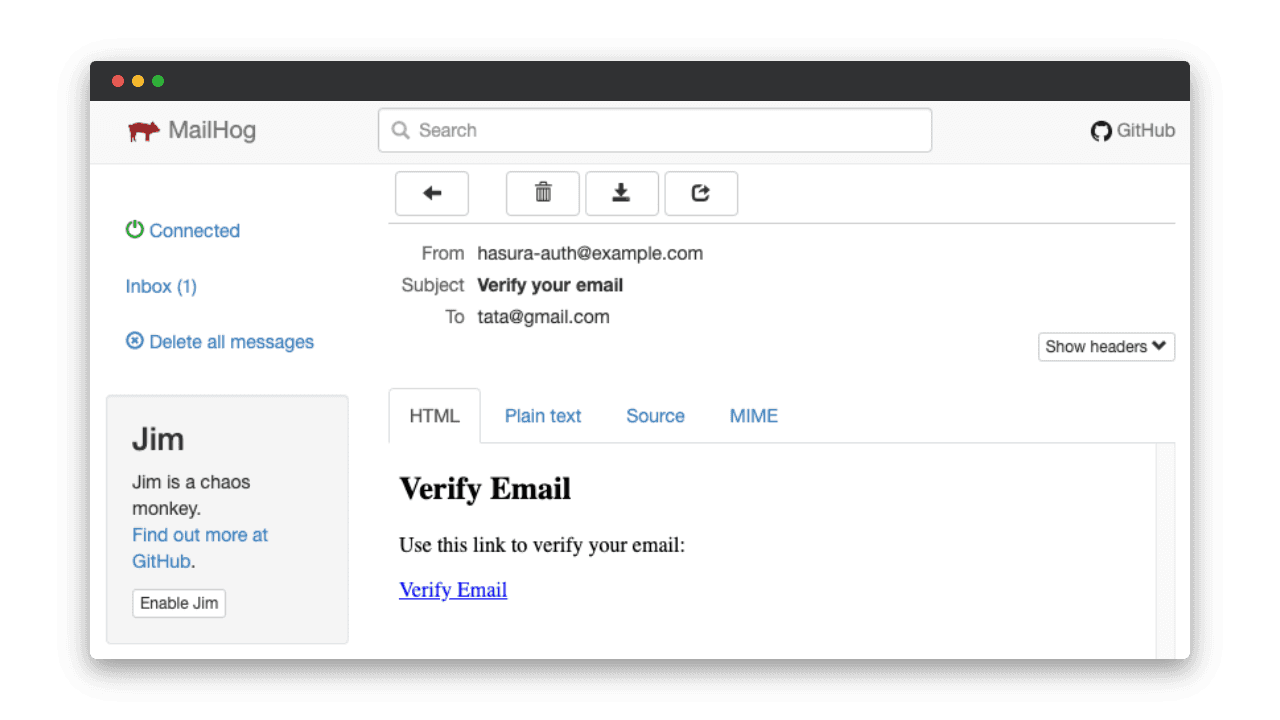
En local, Nhost lance une instance de Mailhog pour aider le développeur à effectuer ses tests.
💡 Mailhog est un outil de test d’e-mail qui permet d’installer et de configurer très facilement un serveur d’e-mail local.
Mailhog est accessible par défaut sur le port 8025.
Persistance de données dans la BDD
On va pouvoir directement créer des tables en base de données grâce à l’interface Hasura accessible en local par défaut sur le port 9695. Un tutoriel est disponible ici.
Les tables doivent être créées dans la base “default” dans le dossier public (les deux autres dossiers sont réservés pour l’authentification et le stockage).
Avec l’interface, vous pouvez définir les informations de votre table comme le nom, les colonnes avec leur type, l’unicité, la valeur par défaut, la clef primaire, les clefs étrangères, la suppression en cascade…
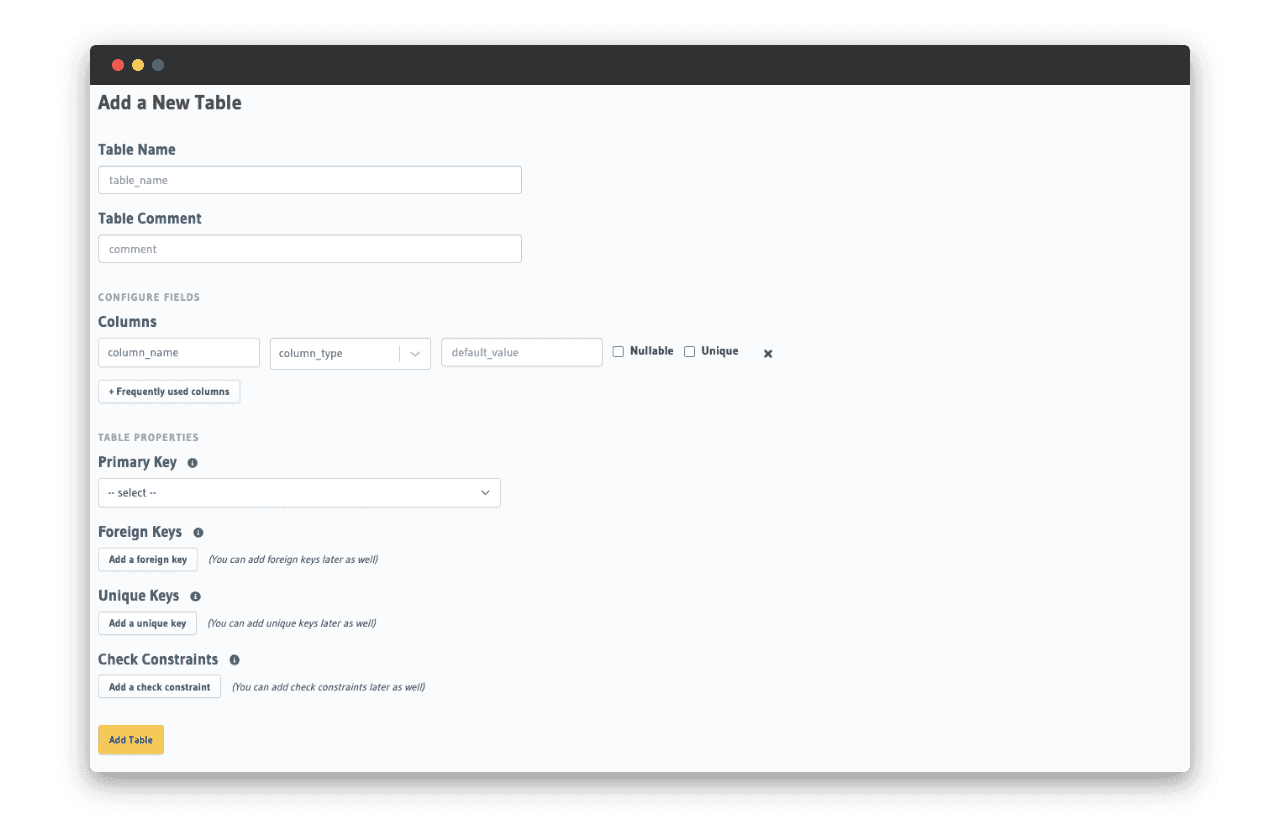
Une fois la table ajoutée, Nhost génère dans le dossier nhost/ des fichiers yaml pour persister la configuration de chaque table.
Nhost génère également les fichiers de migrations. Attention, sur certaines modifications sur l’interface, Hasura n’arrivera pas à déterminer la migration descendante. Un message informe l’utilisateur pour qu’il définisse lui-même la migration.
Les noms des champs GraphQL par défaut sont accessibles dans la partie modification d’une table. Libre à vous de les renommer comme ici ou le nom de sélection des articles a été surchargé par “articles” au lieu de “article” pour plus de cohérence coté frontend :
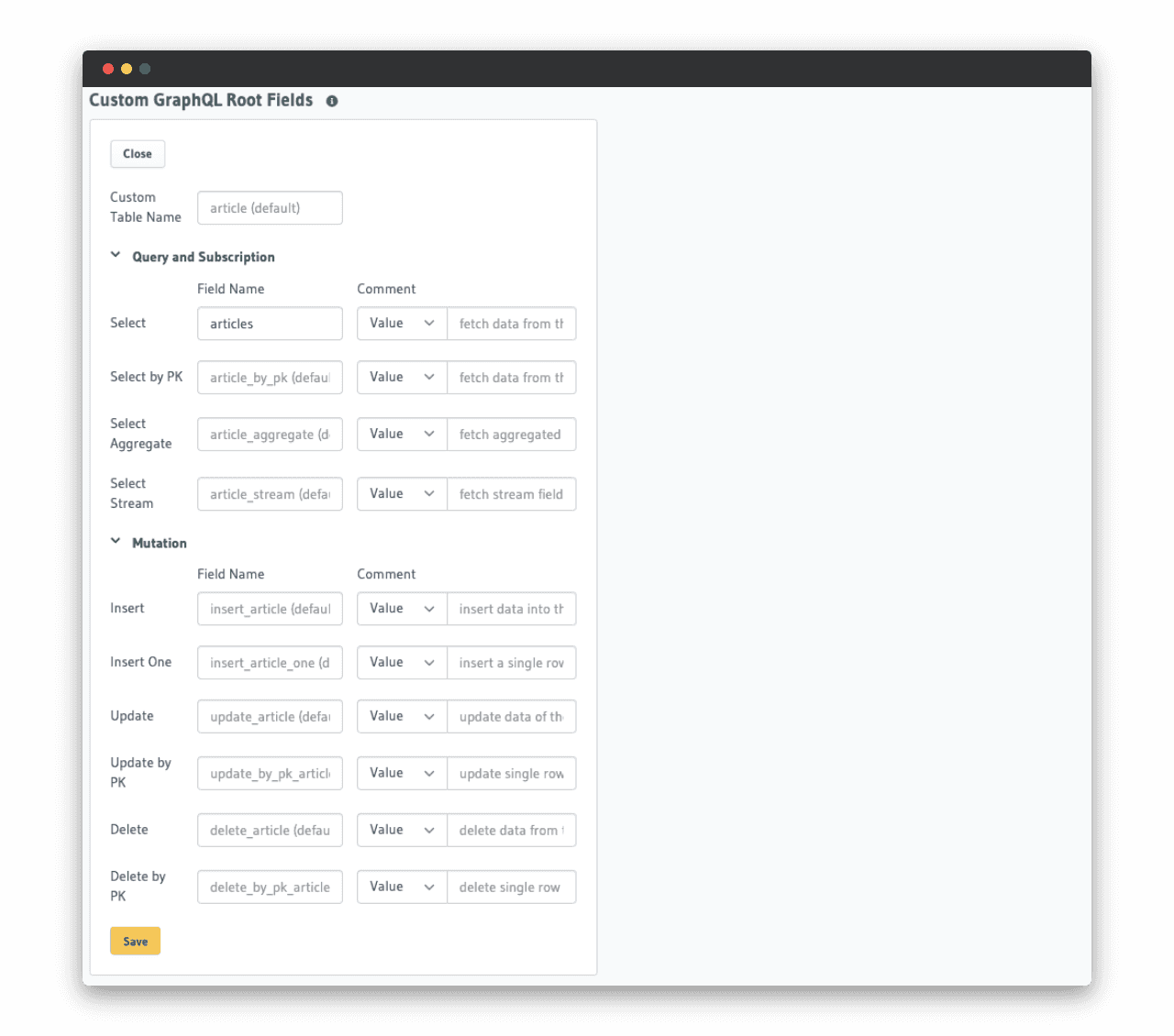
Récupérer des données grâce à GraphQL
Après avoir terminé les modifications backend, nous allons voir comment faire des requêtes depuis le frontend React grâce à GraphQL.
Le client Apollo GraphQL
Pour gérer l’API GraphQL coté frontend, on utilise la solution Apollo GraphQL.
💡 Apollo GraphQL est un client open source proposant une solution serveur GraphQL. Il nous permet de facilement effectuer nos requêtes et gère le cache.
La première étape est donc de rajouter le provider Apollo :
const App = () => (
<NhostReactProvider nhost={nhost}>
<NhostApolloProvider nhost={nhost}> // Add this provider in your App file
<BrowserRouter>
<Router />
</BrowserRouter>
</NhostApolloProvider>
</NhostReactProvider>
);Apollo GraphQL fournit de nombreuses fonctionnalités comme les fragments qui rendent les applications plus scalables ou encore l’optimistic update.
💡 L’optimistic update permet de ne pas attendre la réponse d’une requête serveur avant de rafraîchir l’affichage quand on peut prédire le résultat.
Vous pouvez voir l’ensemble des fonctionnalités de Apollo GraphQL ici.
La librairie graphql-codegen
Dans ce projet, nous utilisons la librairie graphql-codegen pour simplifier l’utilisation de l’API GraphQL.
💡 La librairie graphql-codegen est un outil qui génère des hooks (fichiers .generated.tsx) de query, de souscriptions et de mutations à partir de requêtes GraphQL(fichiers .gql). Plus d’informations sur graphql-codegen ici.
💡 Si vous préférez ne pas utiliser cette librairie, n’hésitez pas à suivre le tutoriel présent dans la documentation officielle de GraphQL ici.
Pour utiliser la librairie, il faut installer les packages relatifs à celle-ci puis ajouter un fichier de configuration codegen.yml à la racine du projet :
schema: 'http://localhost:1337/v1/graphql'
headers:
x-hasura-admin-secret: nhost-admin-secret
documents: 'src/**/*.gql'
generates:
src/graphql/types.ts:
plugins:
- 'typescript'
src/graphql/introspection-result.ts:
plugins:
- fragment-matcher
src/:
preset: near-operation-file
presetConfig:
baseTypesPath: graphql/types.ts
extension: .generated.tsx
plugins:
- typescript-operations
- typescript-react-apollo
config:
withHooks: trueLa récupération de la donnée
Maintenant que les outils sont prêts, nous allons pouvoir récupérer une liste d’articles.
Définissons la requête réalisée par notre page :
subscription ArticleListPage {
articles {
id
...ArticleItem
}
}Nous utilisons une souscription pour profiter du rafraîchissement automatique des données.
ArticleListePage va utiliser notre molécule ArticleItem donc notre requête ArticleListePage utilise un fragment ArticleItem qui lui même définira les données dont il a besoin pour s’afficher.
💡 Plus d’informations sur les fragments ici.
Voici le fragment de ArticleItem :
fragment ArticleItem on article {
id
title
description
}Laissons maintenant la magie du générateur de code opérer grâce à la commande suivante :
pnpm run codegenNous pouvons maintenant afficher la liste des articles dans notre composant ReactJS :
import { Card, CardBody, CardHeader, Text } from '@chakra-ui/react';
type ArticleItemProps = {
fragment: ArticleItemFragment;
};
// this component render an article item
const ArticleItem = ({ fragment }: ArticleItemProps) => (
<Card>
<CardHeader>{fragment.title}</CardHeader>
<CardBody>
<Text>{fragment.description}</Text>
</CardBody>
</Card>
);
import { useArticleListPageSubscription } from './ArticleListPage.generated';
// this component render the page with a map on the list of articles
const ArticleListPage = () => {
// hook generated by codegen
const { data, loading, error } = useArticleListPageSubscription();
if (loading) return <Spinner />;
if (error || !data?.articles) return <Error />;
return (
<>
<h1>Liste des articles</h1>
<div>
{data.articles.map((article) => (
<ArticleItem key={article.id} fragment={article} />
))}
</div>
</>
);
};Pour récupérer des articles, nous devons paramétrer l’autorisation dans Hasura :
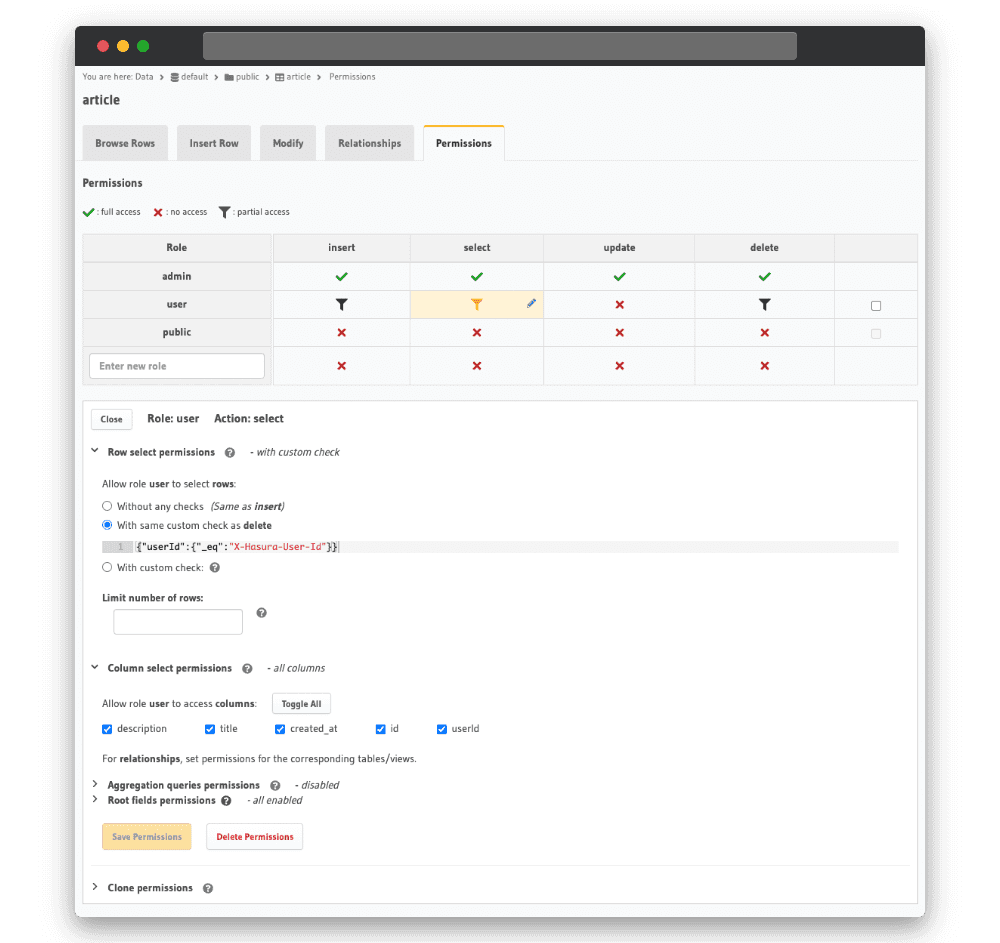
Avant même de coder un formulaire de création d’article, vous pouvez vérifier que l’affichage de votre liste fonctionne en ajoutant des articles à la main via la console Hasura. Il faut laisser les champs id et created_at vide et renseigner le userId avec celui d’un utilisateur crée sur l’application :
Vous obtenez la liste de vos articles en temps réel car nous avons utilisé une souscription et non une query !
Ajouter des données en base
Voyons comment effectuer une mutation simplement grâce à GraphQL. Nous allons ajouter un bouton pour ajouter un article.
Dans un premier temps, il faut écrire la mutation GraphQL :
mutation ArticleCreation($article: article_insert_input!) {
insert_article_one(object: $article) {
id
}
}Après avoir relancé la génération de code, on peut utiliser le hook généré dans la callback de soumission du formulaire de la création d’un article :
import { useArticleCreationMutation } from './ArticleCreationModalForm.generated';
// hook generated by codegen
const [createArticle, { loading }] = useArticleCreationMutation();
const onSubmit = async () => {
if (areTitleAndDescriptionNotEmpty()) {
const { errors } = await createArticle({
variables: {
article: {
title,
description,
},
},
});
if (!errors) {
resetFields();
onClose();
toastSuccess('Article créé avec succès');
} else {
toastError("Erreur lors de la création de l'article");
}
}
};Il ne reste plus qu’à ajouter l’autorisation pour un utilisateur de pouvoir insérer une donnée dans la table “article”.
Ici, tous les utilisateurs peuvent insérer une ligne en spécifiant uniquement le titre et la description. Le userId sera automatiquement renseigné à partir du userId de la session grâce aux “Column preset”.
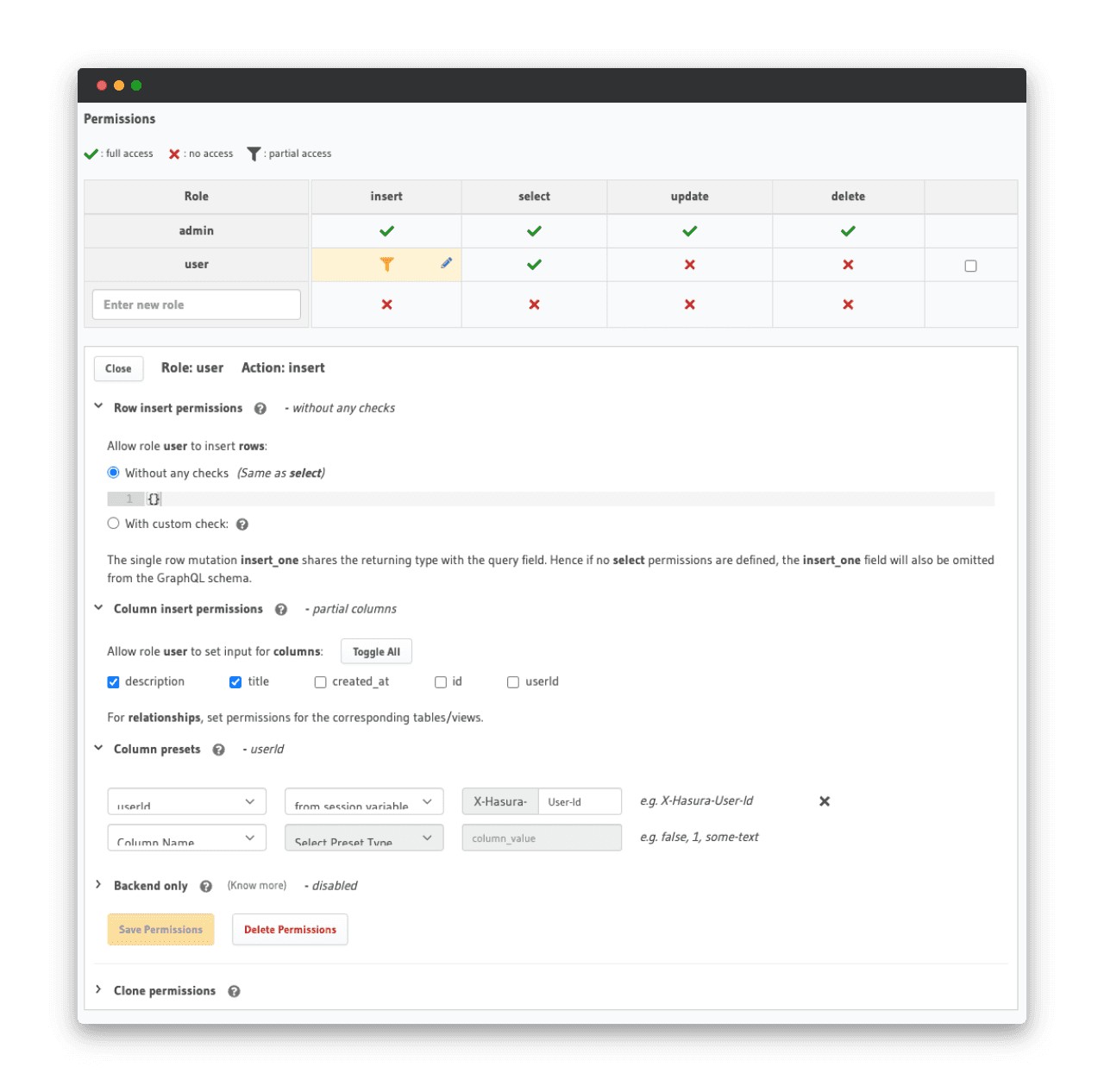
L’utilisateur peut maintenant ajouter des articles.
Autorisations avec custom check
Intéressons nous maintenant à une modification en base de données qui ne soit pas réalisable par l’ensemble des utilisateurs, comme l’ajout d’un article, mais seulement une partie d’entre eux. C’est le cas de la suppression d’un article : seulement l’auteur de l’article à le droit de le supprimer.
Commençons par écrire la mutation qui va supprimer un article :
mutation DeleteArticle($id: uuid!) {
delete_article_by_pk(id: $id) {
id
}
}Il faut donc ajouter une vérification sur la requête de suppression d’un article.
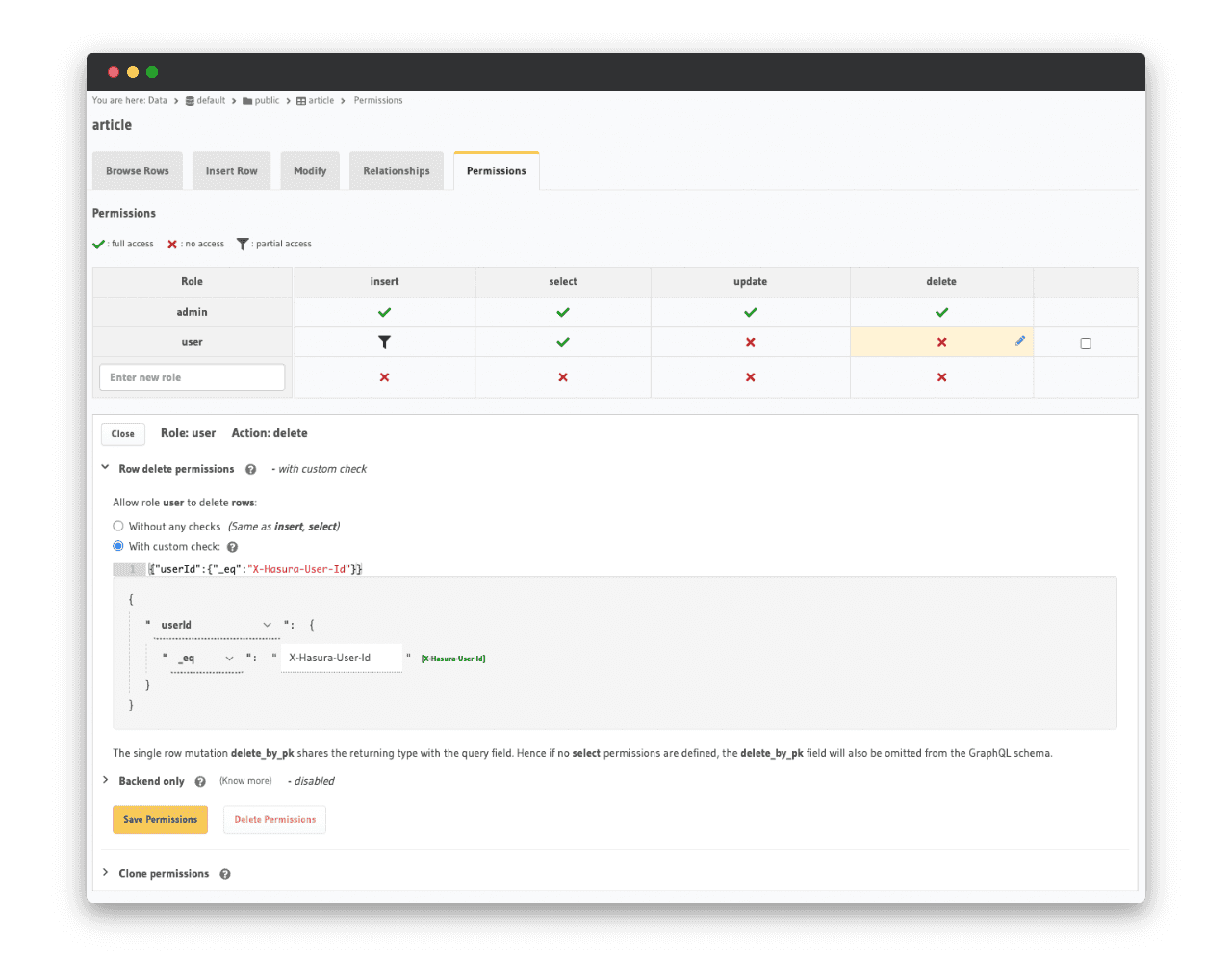
À noter que, par défaut, le rôle admin a le droit à toutes les opérations sur l’ensemble des tables.
Les clouds fonctions
Définition de la cloud fonction dans le back-end
Pour utiliser les clouds fonctions, il va falloir définir un serveur express dans un dossier functions/ coté backend. Un tutoriel explique la marche à suivre ici.
L’ensemble des fichiers présents dans le dossier functions/ seront utilisés pour générer des routes. Si vous voulez ajouter des fichiers utilitaires par exemple qui ne constituent pas une route, alors vous devez les placer dans des dossiers préfixés par un underscore.
Dans l’exemple, nous allons utiliser une route pour générer un token à partir d’une clef et d’un secret.
Ce cas d’usage nécessite une cloud fonction car le secret ne peut pas être présent coté front.
Il suffit de définir la fonction dans getToken.ts :
import { Request, Response } from 'express'
export default (req: Request, res: Response) => {
guardAuth(context); // Check if user is authenticated (function in _utils/)
const { key } = req.body.key;
const token = generateInviteToken(key); // function in _utils/
return res.status(200).send({ token });
}Si vous clonez le répertoire Git, vous pourrez voir que nous avons défini une surcouche qui simplifie la définition de cloud fonctions dans le dossier utils/.
Appel d’une cloud fonction dans le frontend
Maintenant que la cloud fonction est définie coté back-end, nous pouvons l’utiliser coté frontend :
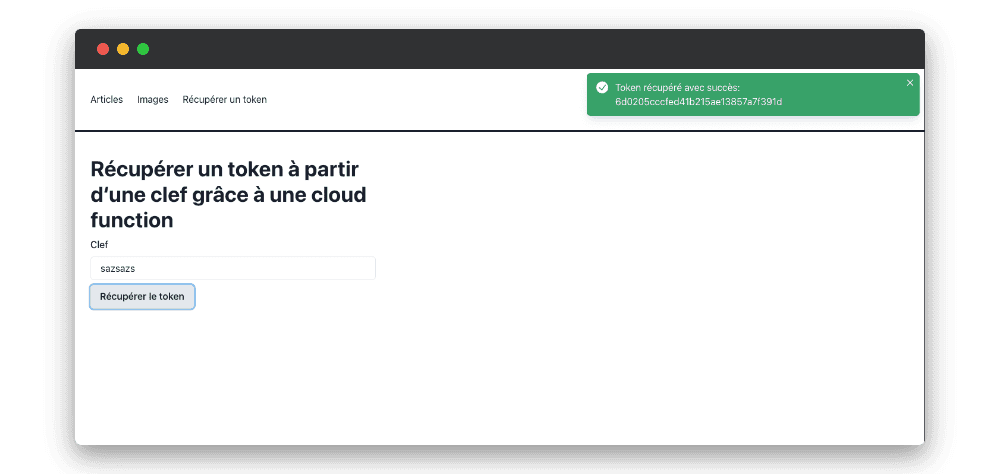
Vous pouvez utiliser le SDK javascript fournit par Nhost dans les clouds fonctions pour gérer l’authentification, le stockage, les appels GraphQL…
Le stockage
Voyons maintenant comment Nhost permet l’upload et l’affichage de fichier.
N’hésitez pas à aller voir le tutoriel ici.
Upload d’un fichier
L’utilisateur va pouvoir facilement uploader des fichiers grâce au hook fourni par le SDK.
import { useFileUpload } from '@nhost/react';
import { useState } from 'react';
const [loading, setLoading] = useState<boolean>(false);
const { upload } = useFileUpload();
const onSubmit = async (file: File) => {
try {
await setLoading(true);
const { isError } = await upload({ file, name: file.name });
if (isError) throw Error('Error');
onClose();
toastSuccess('Fichier upload avec succès');
} catch (error) {
toastError("Erreur lors de l'upload du fichier");
} finally {
setLoading(false);
}
};À la différence des fonctionnalités d’authentification, il n’y a pas de gestion de l’état loading. Nous l’avons donc géré avec un useState.
Attention à ne pas oublier l’ajout de l’autorisation pour un utilisateur d’insérer une image en base de données.
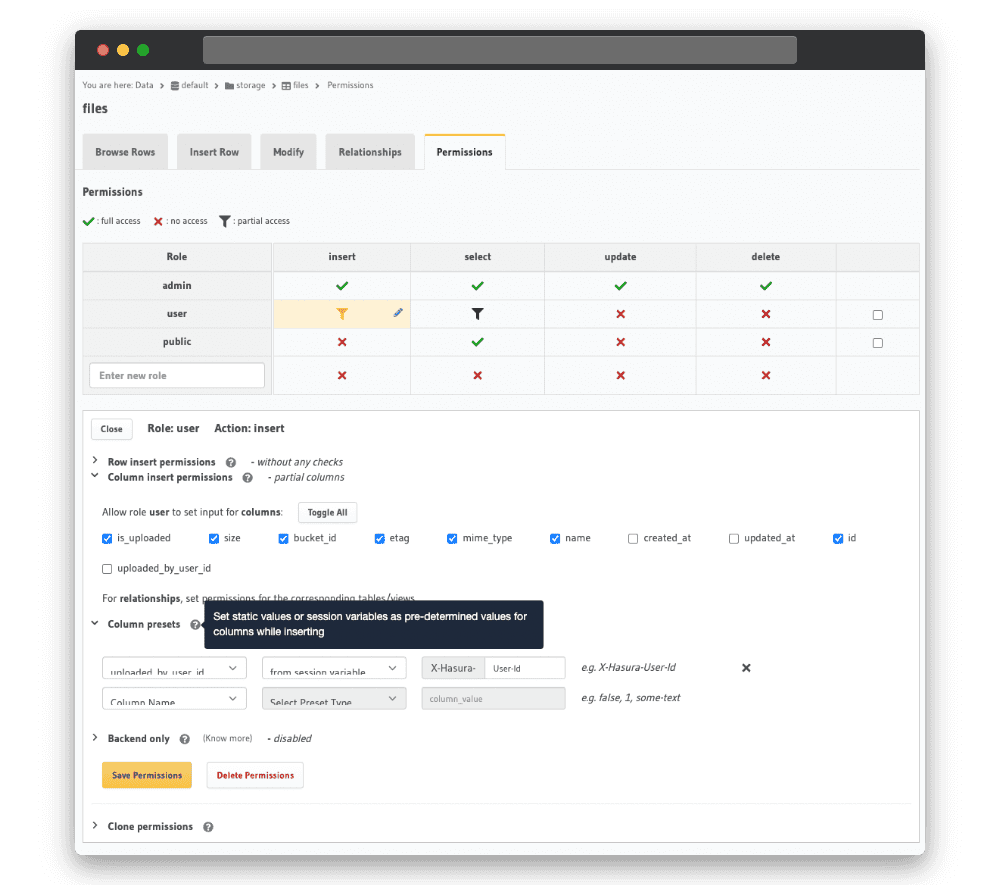
On utilise la colonne preset pour définir l’id de l’utilisateur qui a uploadé l’image. Cela va nous servir après pour qu’un utilisateur ne puisse voir que ses images à lui.
L’utilisateur peut maintenant uploader un fichier.
Affichage de la liste des fichiers
Il faut commencer par récupérer la liste des ids de fichiers grâce à une requête GraphQL :
subscription ImageListPage {
files {
id
}
}Ajoutons également l’autorisation de récupérer les ids des images pour un utilisateur connecté.
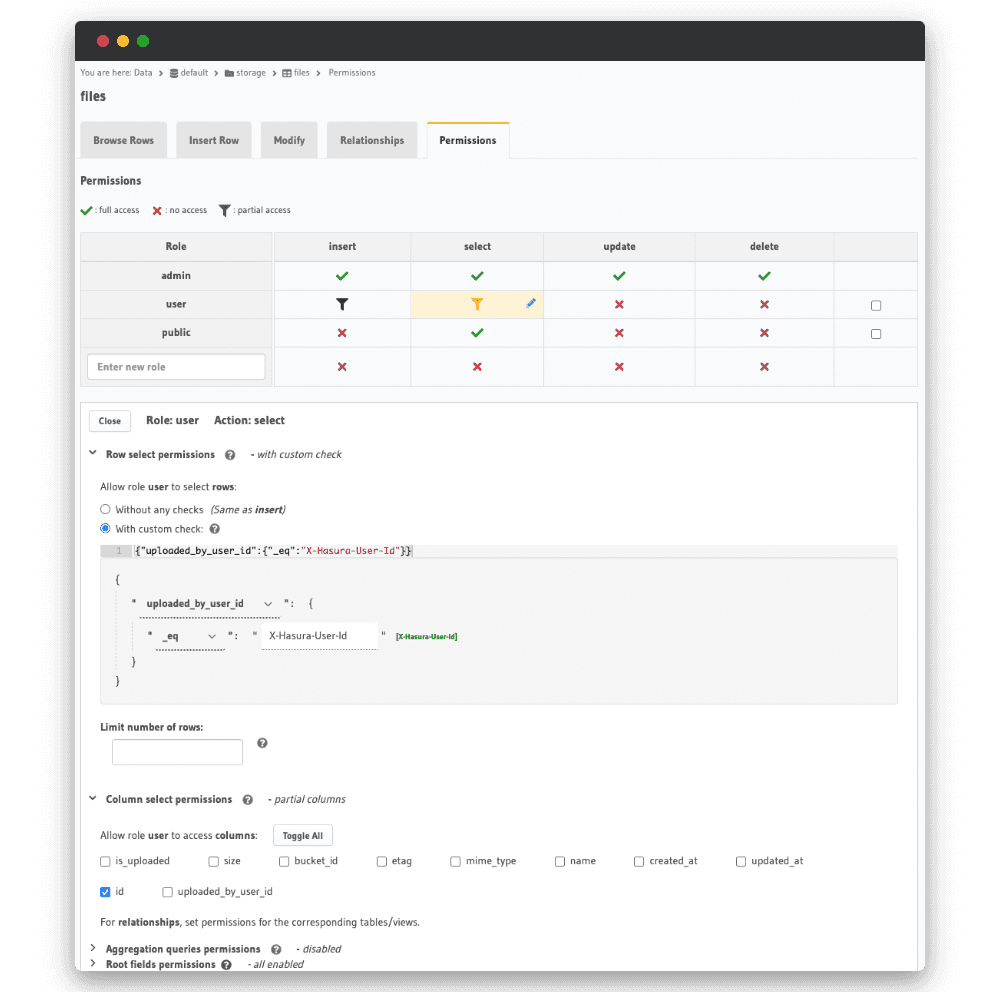
Pour qu’un utilisateur récupère seulement ses ids, nous définissons une vérifications sur le champs uploaded_by_user_id.
N’oubliez pas d’appeler la commande de codegen !
Grâce aux ids des images, nous allons maintenant pouvoir déterminer l’URL à laquelle l’image est accessible pour pouvoir l’afficher :
import { Flex, Heading, Image, Spinner, VStack } from '@chakra-ui/react';
import nhost from '../../../nhost';
import { useImageListPageSubscription } from './ImageListPage.generated';
const ImageListPage = () => {
// hook generated by codegen
const { data, loading, error } = useImageListPageSubscription();
if (loading) return <div>Chargement</div>;
if (error || !data?.files) return <div>Erreur</div>;
return (
<VStack>
<Heading>Liste des images</Heading>
<Flex gap={6} wrap="wrap">
{data.files.map((file) => {
// use getPublicUrl to compute the url of the resource
const url = nhost.storage.getPublicUrl({ fileId: file.id });
return <Image key={file.id} src={`${url}?=w250`} />;
})}
</Flex>
</VStack>
);
};
export default ImageListPage;On peut voir ici que l’on spécifie dans l’URL la résolution des images récupérées grâce à une query param.
Les images ne s’affiche pas parce qu’elles ne sont pas publique, pour remédier à ca il faut rajouter une ligne dans la table de permission des fichiers :
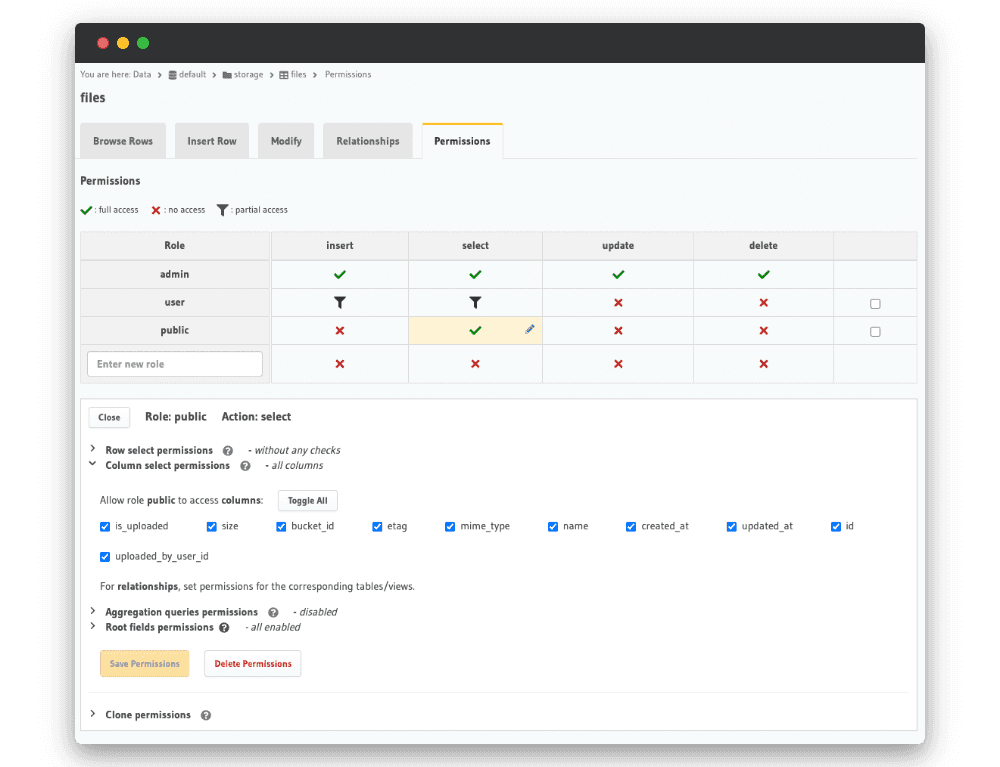
À noter que dans notre cas d’usage, les utilisateurs peuvent accéder à l’ensemble des images. Si ça n’est pas le cas, Nhost fournit des URLs pré-signées pour limiter l’autorisation de certains fichiers.
L’utilisateur n’accède qu’aux images qu’il a lui-même uploadé car il ne récupère que ses ids. Néanmoins, toutes les images sont publiques et donc accessibles à partir du moment ou l’on a son id.
Pour éviter cela, Nhost fournit des URLs pré-signées pour limiter l’autorisation de certains fichiers.
Déploiement de l’application
Maintenant que nous avons fini le développement de notre application en local, intéressons-nous au déploiement pour faire profiter le monde entier de cette magnifique application.
Le déploiement du back-end
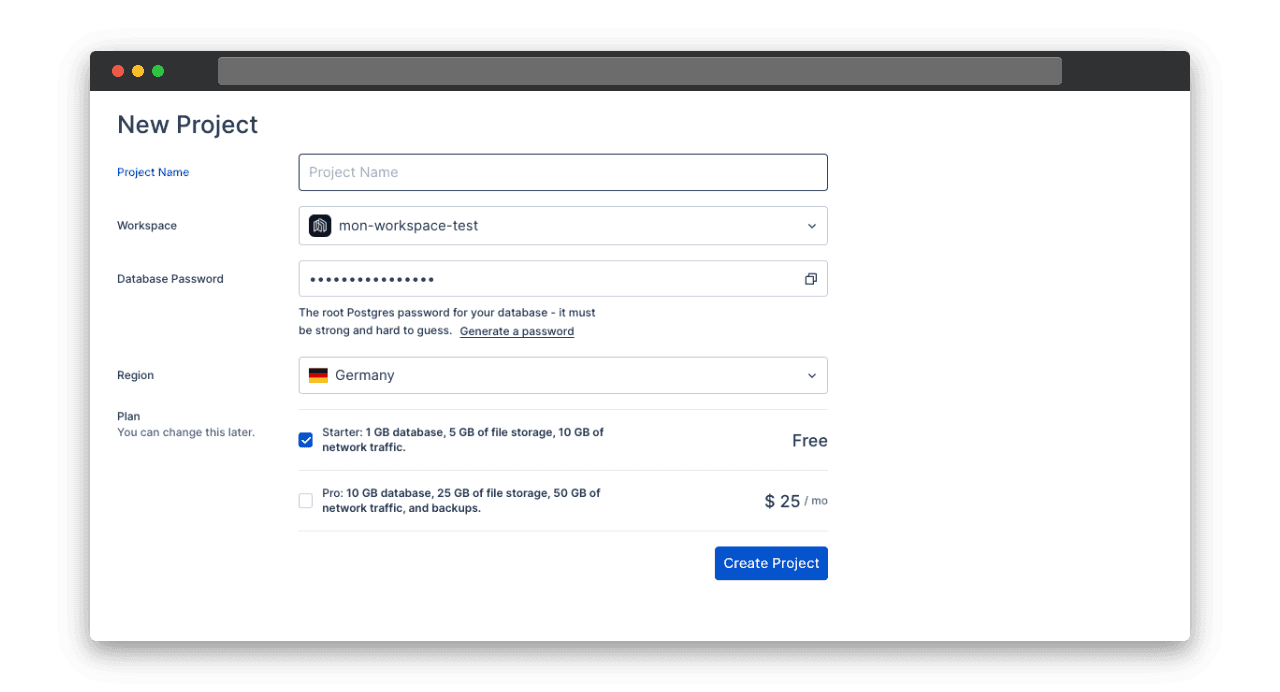
Pour déployer le backend il faut commencer par se créer un compte sur nhost.io.
Ensuite, il faut créer un workspace et un projet :
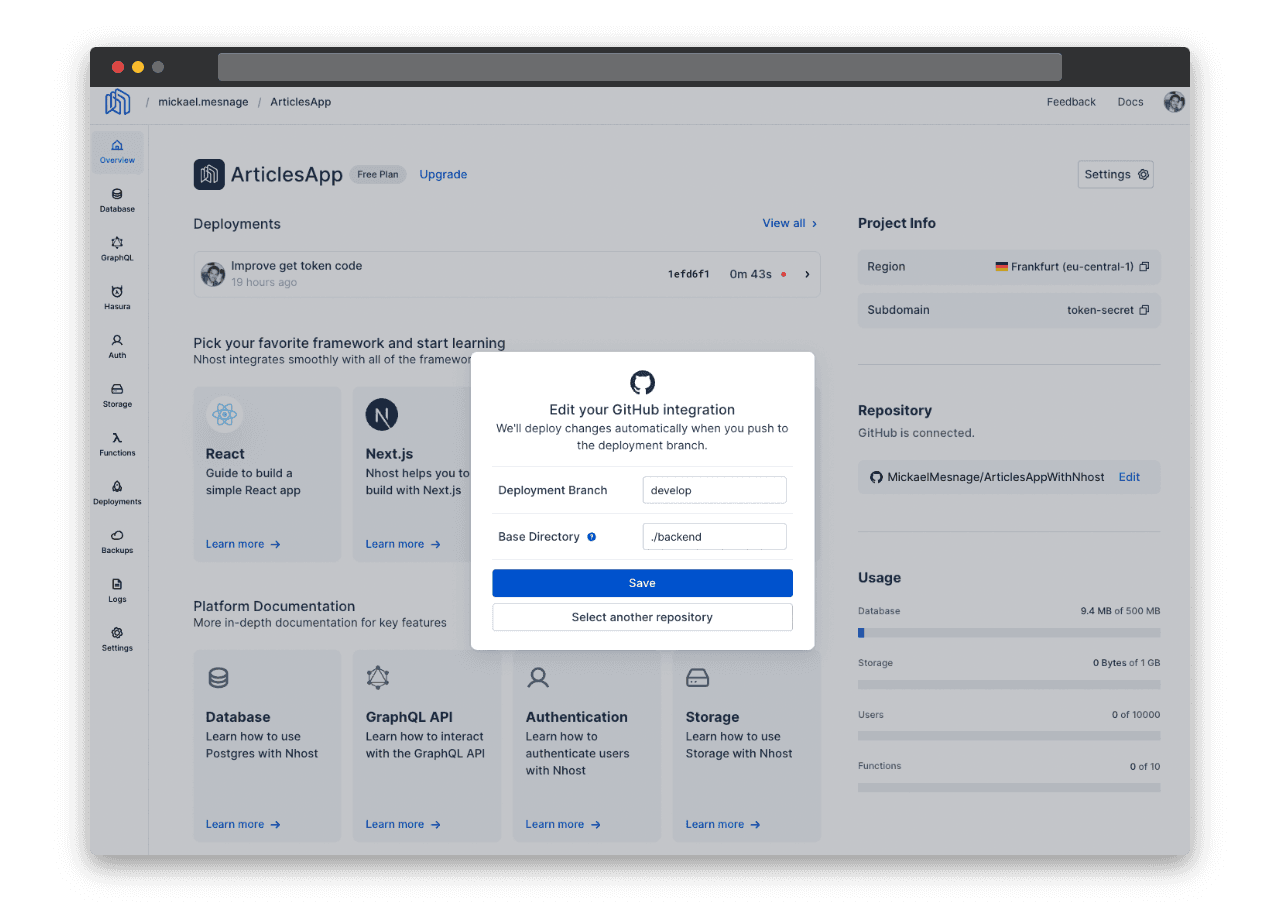
Il faut ensuite connecter le projet Nhost au répertoire Github :
Le déploiement du frontend
Pour déployer le frontend lié à un backend Nhost, Nhost conseille d’utiliser Netlify ou Vercel.
Pour le déploiement de ce projet, nous avons choisi la solution Netlify.
Pour être rattaché au projet Nhost, nous avons défini plus haut un NhostClient, prenant en paramètre le sous domaine et la région, utilisés par nos deux providers.
Nous allons utiliser des variables d’environnement pour adapter les valeurs suivant l’environnement sur lequel se lance l’application ReactJS.
💡 Pour définir des variables d’environnement avec un projet ReactJS généré avec vite comme c’est le cas ici, il faut créer un fichier .env à la racine dans lequel il faut définir des variables avec un prefix VITE_
Voici le .env utilisé en local :
VITE_NHOST_SUBDOMAIN=localhost
VITE_NHOST_REGION=Ces variables peuvent maintenant être utilisées dans le code comme ceci :
import { NhostClient } from '@nhost/react';
// you can handle subdomain and region with environnement vars
const nhost = new NhostClient({
subdomain: import.meta.env.VITE_NHOST_SUBDOMAIN,
region: import.meta.env.VITE_NHOST_REGION,
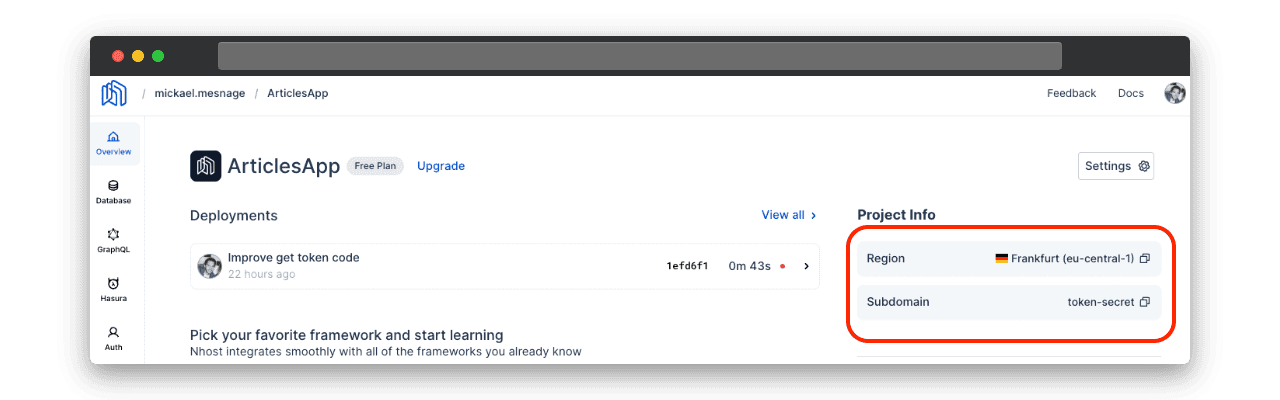
});Pour définir, les variables d’environnements utilisées par Netlify, il faut d’abord les récupérer sur l’application Nhost :
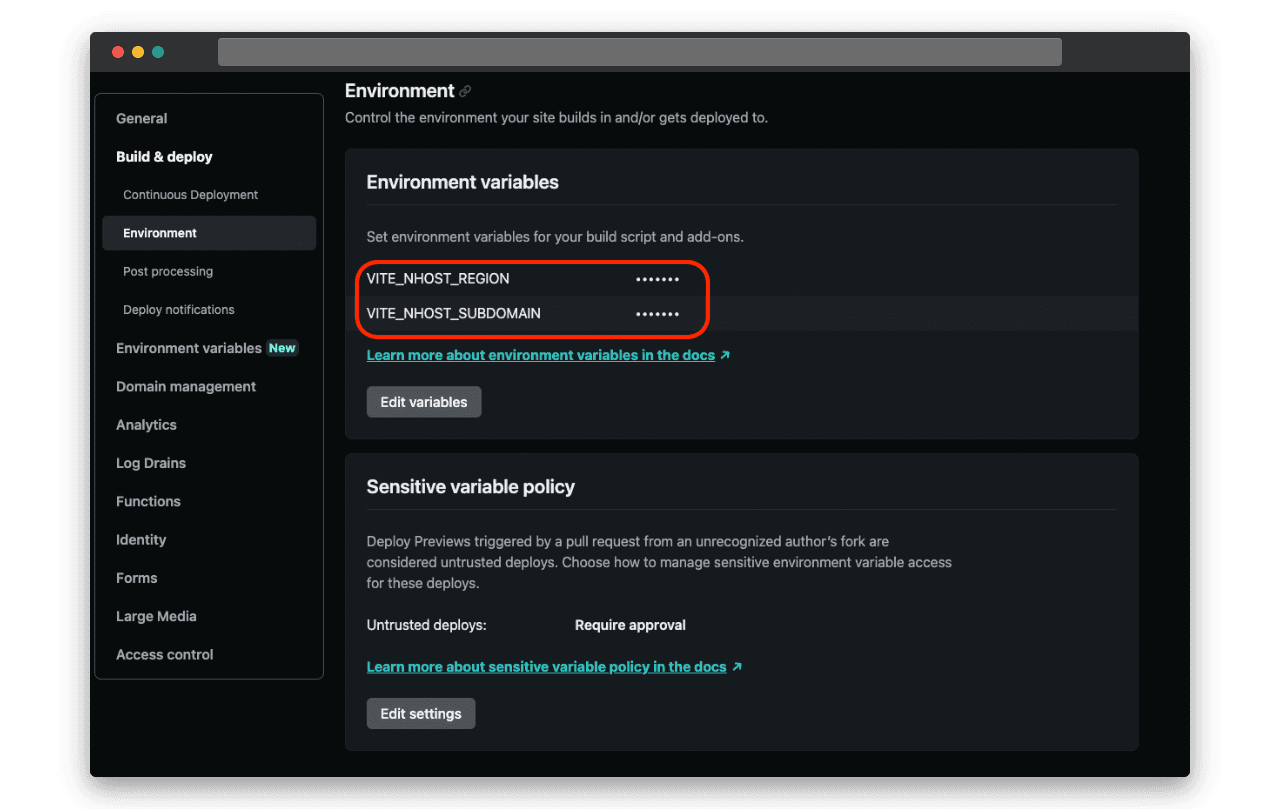
Puis les définir sur l’interface de Netlify :
En résumé :
Nhost est un super outil qui propose de nombreuses fonctionnalités pour rapidement développer son back-end.
En effet, en quelques clics et quelques lignes de code, on peut déployer une application avec la base d’un site web comme l’authentification, le stockage de fichiers…
Ce côté magique peut être un peu déroutant pour le développeur au début, mais c’est une question de temps pour comprendre la mécanique de la plateforme.
Utiliser Nhost peut être intéressant pour des applications de petite ou moyenne taille. En revanche, pour une application dense avec une grosse équipe, il est certainement plus intéressant de boot-strapper soit même son back-end pour avoir un contrôle sur l’architecture.
Il est vrai que la plateforme est encore jeune ce qui peut expliquer un manque de documentation sur certaines fonctionnalités ainsi qu’une communauté timide.
L’utilisation de GraphQL est un énorme plus par rapport à la plupart des alternatives du marché car cela permet de construire des applications plus robustes et plus scalables.
En revanche, pas d’analytique web avec Nhost contrairement à certains de ses concurrents comme Firebase.
💡 L’analytique Web permet à une entreprise de recueillir des données sur les visiteuses et visiteurs qui se rendent sur son site Web (nombre de visiteurs, nombre de pages consultées, mode d’accès au site, durée moyenne des visites…).



