Construire un copilote IA qui apporte une vraie valeur (et pas un gadget)
14 min de lecture
Mis à jour le
Les copilotes IA sont partout. Depuis le succès de ChatGPT, GitHub Copilot et Microsoft 365 Copilot, chaque éditeur de logiciel intègre son propre assistant intelligent. Les dépenses mondiales en IA dépassent 300 milliards de dollars en 2026 (IDC), et 72 % des entreprises ont au moins un déploiement IA en production. GitHub Copilot est adopté par 90 % des entreprises du Fortune 100, et 38 % des knowledge workers utilisent l’IA générative au quotidien. Le problème ? La majorité de ces copilotes restent des gadgets marketing, abandonnés quelques semaines après leur lancement par des utilisateurs déçus. Seuls 6 % des entreprises ont réussi à faire passer leurs projets d’IA générative au-delà de la phase pilote (Gartner).
Quand on souhaite créer un SaaS IA ou enrichir un produit existant avec un copilote, l’enjeu reste de résoudre un problème utilisateur concret. Construire un copilote IA qui délivre une vraie valeur demande bien plus qu’ajouter une API LLM dans une interface. Cela implique une réflexion produit structurée, une compréhension fine des besoins réels, et des choix d’architecture qui permettent à l’IA de s’intégrer naturellement dans les workflows existants. D’autant plus que le marché évolue rapidement vers des copilotes agentiques, capables d’exécuter des tâches de bout en bout et d’orchestrer plusieurs outils simultanément. En 2026, les fonctionnalités IA dans un SaaS sont devenues un prérequis du marché : après avoir été un différenciateur en 2024 puis une attente en 2025, elles sont désormais un standard incontournable.
Ce qu'il faut retenir sur la conception d'un copilote IA
Un bon copilote ne part pas de la techno, mais des pain points : il doit résoudre 2 à 4 tâches fréquentes, chronophages et critiques – pas “tout faire un peu”.
Les use cases se valident avant de se développer : protos low-fi, POC rapides, tests avec de vrais utilisateurs évitent de construire un gadget brillant mais inutile.
L’architecture doit servir le produit, pas l’inverse : RAG pour la recherche factuelle, LLM puissant pour la synthèse, agents + function calling + MCP pour les actions… chaque brique doit être choisie en fonction du cas d’usage et des contraintes de coûts/latence. Avec la baisse de 80 % des tarifs API entre 2025 et 2026, le routage intelligent entre modèles est devenu encore plus stratégique.
Un copilote utile est presque invisible : intégré là où l’utilisateur travaille déjà (grâce au protocole MCP pour les connexions multi-outils, adopté par tous les grands fournisseurs d’IA), il propose des actions concrètes plutôt que des réponses verbeuses, réduit la friction (suggestions contextuelles, interfaces hybrides) et reste transparent sur ses limites.
La confiance et le contrôle sont non négociables : l’utilisateur garde la main (édition avant envoi, validation des actions), sait comment ses données sont utilisées, et comprend ce que le copilote fait “en coulisses” grâce au signalement IA et à la transparence algorithmique, condition clé pour une adoption durable. Les frameworks de gouvernance (audit trails, SSO, contrôles admin) sont devenus un prérequis pour le déploiement en entreprise.
1. Identifier les vrais problèmes : prioriser les use cases qui comptent
La première erreur dans la conception d'un copilote IA est de vouloir tout faire. Un chatbot générique qui répond à n'importe quelle question semble séduisant sur le papier, mais il dilue la valeur perçue et complique l'adoption. Pour qu'un copilote soit utile, il doit d'abord résoudre des problèmes spécifiques et récurrents.
Partir des pain points réels
Avant de penser technologie, posez-vous cette question : quelles sont les tâches les plus chronophages ou frustrantes pour vos utilisateurs ? Dans un outil de gestion de projet, ce n'est peut-être pas "répondre à toutes les questions possibles", mais plutôt "retrouver rapidement le statut d'une tâche bloquante" ou "générer un résumé des actions en retard". Dans un CRM, il s'agira peut-être d'enrichir automatiquement une fiche contact ou de suggérer le prochain meilleur action commercial.
L'objectif est d'identifier 2 à 4 use cases prioritaires qui, s'ils sont bien exécutés, changeront significativement la vie de vos utilisateurs. Ces use cases doivent être :
-
Fréquents : l'utilisateur y est confronté régulièrement
-
Chronophages : la tâche prend du temps ou demande plusieurs clics
-
Critiques : l'échec ou le retard sur cette tâche a un impact business
Une directrice marketing qui passe 30 minutes chaque matin à compiler les performances de ses campagnes dans différents outils bénéficiera énormément d'un copilote qui génère ce rapport en une seule commande. En revanche, proposer un assistant pour reformuler ses emails n'apportera qu'une valeur marginale.
Valider avant de développer
Une fois vos use cases identifiés, ne vous précipitez pas sur le développement. Validez-les avec de vrais utilisateurs. Créez des prototypes basse fidélité, des scripts de conversation, ou même des simulations manuelles (un humain qui joue le rôle du copilote). Cette phase de validation permet de s'assurer que vous construisez quelque chose dont les gens ont réellement besoin, et non ce que vous imaginez qu'ils veulent.
Pour accélérer cette phase de validation, nous utilisons souvent des outils de prototypage rapide comme Vercel AI SDK (version 6, avec support natif des agents via ToolLoopAgent, approbation humaine des actions et DevTools de débogage) ou LangGraph (checkpointing intégré, human-in-the-loop et composition de sous-graphes), qui permettent de tester des interactions IA fonctionnelles en quelques jours. Plutôt que de partir sur une architecture complexe dès le départ, nous privilégions des POCs (proof of concept) légers qui exposent rapidement la valeur du copilote aux utilisateurs pilotes.
2. Concevoir une architecture qui sert le produit (et pas l'inverse)
Une fois les use cases validés, vient la question de l'architecture. Trop souvent, les équipes construisent leur copilote autour d'une stack technique qu'elles trouvent excitante, sans se demander si celle-ci sert réellement l'expérience produit. Résultat : des latences insupportables, des réponses approximatives, ou des fonctionnalités inutilisables en production.
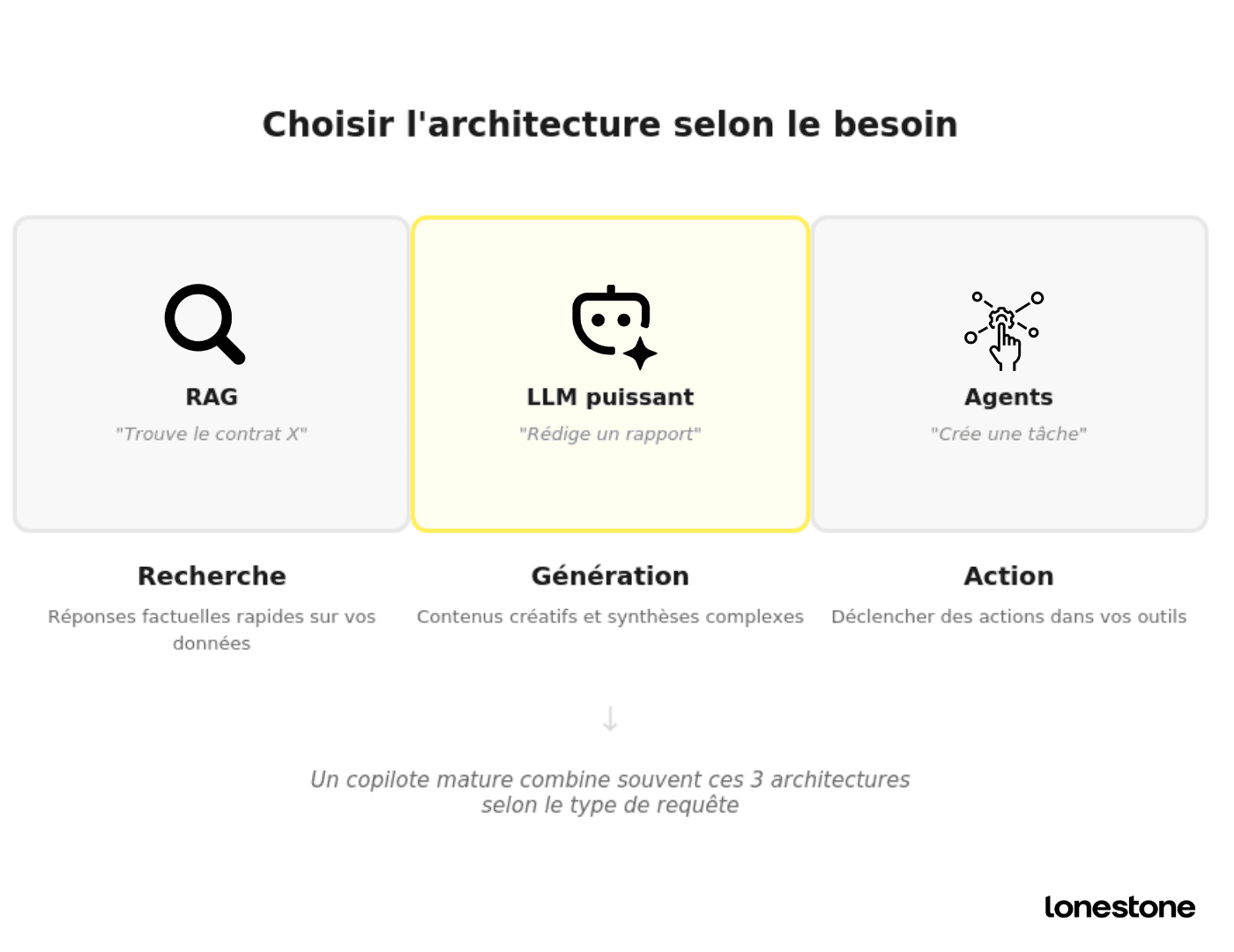
Choisir le bon niveau d'intelligence
Tous les use cases ne nécessitent pas un LLM de dernière génération. Parfois, une recherche sémantique bien calibrée suffit. Parfois, un modèle léger et rapide (comme Gemini Flash ou Claude Haiku) sera préférable à un modèle frontier plus lent et coûteux. La clé est de choisir le bon outil pour le bon problème.
Quelques principes d'architecture :
-
Pour des tâches de recherche et de restitution d'information (ex : "trouve-moi le contrat client X"), privilégiez une architecture RAG (Retrieval-Augmented Generation) avec une base vectorielle performante comme Pinecone, Weaviate ou Qdrant. En 2026, le marché s'est consolidé autour de ces trois acteurs, chacun avec ses forces : Pinecone pour sa simplicité serverless (facturation à l'usage), Weaviate pour sa recherche hybride (vectorielle + BM25 en une seule requête), Qdrant pour ses performances en filtrage avancé grâce à son implémentation Rust. Cela garantit des réponses rapides et factuelles, ancrées dans vos données métier.
-
Pour des tâches de génération créative ou de synthèse complexe (ex : "rédige un rapport de synthèse mensuel"), optez pour un LLM frontier comme GPT-5.5 (sorti le 23 avril 2026), Claude Opus ou Gemini 2.5 Pro. Ces modèles offrent des fenêtres de contexte allant de 200K à 1 million de tokens, ce qui permet de traiter des documents volumineux en une seule passe. Les tarifs s'échelonnent selon les capacités : GPT-5.5 se situe à 5 $/M tokens en entrée et 30 $ en sortie, Claude Opus à 5 $ et 25 $, Gemini 2.5 Pro à 1,25 $ et 10 $. Pour les tâches simples, des modèles légers comme Gemini Flash-Lite (0,10 $/M tokens en entrée) offrent un rapport qualité/prix imbattable.
-
Pour des actions structurées (ex : "crée une tâche et assigne-la à Pierre"), pensez agents et function calling. Le copilote agit directement dans votre système. Le standard MCP (Model Context Protocol), initié par Anthropic et adopté par OpenAI, Google, Microsoft et Amazon, a dépassé les 97 millions de téléchargements mensuels SDK (Python + TypeScript). Sa feuille de route 2026 cible la scalabilité du transport (HTTP stateless derrière load balancers), la communication inter-agents et la maturité entreprise (audit trails, auth SSO, gateways). Plutôt que de coder une intégration spécifique pour chaque service, MCP offre un point d'entrée unique. Le protocole complémentaire A2A (Agent-to-Agent) permet en outre aux agents de collaborer entre eux.
-
Pour des workflows complexes et multi-étapes, explorez les architectures multi-agents. Plutôt qu'un seul copilote monolithique, plusieurs agents spécialisés collaborent : un agent pour la recherche d'information, un autre pour l'analyse, un troisième pour l'exécution d'actions. Des frameworks comme LangGraph permettent d'orchestrer ces agents avec gestion d'état persistant (checkpointing), branchements conditionnels, composition de sous-graphes et intervention humaine (human-in-the-loop). Microsoft illustre cette tendance avec Copilot Cowork, qui orchestre des agents capables d'exécuter des tâches multi-étapes de façon autonome tout en gardant l'humain dans la boucle pour les décisions critiques.
Anticiper la montée en charge
Un copilote qui fonctionne bien pour 10 beta-testeurs peut s'effondrer avec 10 000 utilisateurs. Dès la conception, posez-vous les questions de scalabilité : combien de requêtes par seconde devez-vous supporter ? Quels sont les coûts d'API associés ? Comment optimiser les appels pour réduire la latence ? Avec des tarifs LLM allant de 0,10 $ à 30 $ par million de tokens d'entrée selon le modèle (et des tokens de sortie 3 à 8 fois plus chers que les tokens d'entrée), le choix du bon niveau d'intelligence pour chaque tâche a un impact direct sur la rentabilité du produit. La bonne nouvelle : les prix API ont chuté d'environ 80 % entre 2025 et 2026, ce qui rend les architectures multi-modèles plus accessibles.
Chez Lonestone, nous structurons souvent nos architectures avec un système de cache intelligent qui mémorise les réponses fréquentes et un rate limiting par utilisateur pour contrôler les coûts. Pour les projets critiques, nous mettons en place un fallback vers des modèles plus légers (Gemini Flash-Lite, Claude Haiku) en cas de surcharge du modèle principal, et un routage intelligent qui sélectionne automatiquement le modèle adapté à la complexité de chaque requête. Une tendance émergente : le pattern multi-modèle critique, où un premier modèle génère une réponse et un second la vérifie (approche adoptée par Microsoft Copilot avec GPT + Claude). Ces choix techniques invisibles pour l'utilisateur final font toute la différence entre un copilote qui fonctionne et un copilote qui frustre.
3. Soigner l'expérience utilisateur : un copilote utile est un copilote invisible
L'architecture la plus brillante ne sauvera pas un copilote mal intégré. L'expérience utilisateur est ce qui fait qu'un copilote sera adopté massivement ou ignoré. Et contrairement aux idées reçues, un bon copilote IA n'est pas toujours celui qui impressionne par ses prouesses techniques, mais celui qui se fait oublier en s'intégrant naturellement dans le flux de travail.
Réduire la friction cognitive
Les utilisateurs ne veulent pas apprendre un nouveau langage pour interagir avec votre copilote. Ils veulent poser des questions comme ils les poseraient à un collègue, et obtenir des réponses exploitables immédiatement. Cela signifie :
-
Éviter le syndrome de la page blanche : ne laissez jamais votre utilisateur face à un champ vide sans savoir quoi demander. Le pattern "suggested prompts" est désormais un standard établi : proposez des suggestions contextuelles, des use cases types, des exemples de commandes adaptés au contexte actuel de l'utilisateur. En 2026, les meilleures interfaces vont plus loin avec des composants dynamiques qui s'adaptent à l'intention détectée et des layouts génératifs qui réorganisent l'interface selon la tâche en cours. Une directrice innovation qui découvre votre outil pour la première fois doit comprendre instantanément ce que le copilote peut faire pour elle.
-
Privilégier les actions aux conversations : un copilote n'est pas un chatbot de support client. Si l'utilisateur demande "montre-moi les tâches en retard", ne répondez pas par un long paragraphe explicatif. Affichez directement la liste filtrée, avec des boutons d'action pour relancer ou réassigner ces tâches. Les interfaces hybrides (combinant texte, visuels et actions cliquables) offrent une bien meilleure expérience que le chat pur.
-
Signaler clairement le contenu généré par IA : le pattern "AI notice" s'est imposé comme une bonne pratique. Chaque réponse du copilote doit être identifiable comme générée par l'IA, pour encourager l'utilisateur à évaluer l'information plutôt qu'à l'accepter aveuglément. Si une question sort du scope, dites-le clairement et proposez une alternative.
-
Intégrer une boucle de feedback : permettre aux utilisateurs de noter les réponses (pouce haut/bas, signalement d'erreur) alimente un cycle d'amélioration continue. Ces retours sont précieux pour affiner les prompts, ajuster le RAG et identifier les use cases émergents. Les études UX de 2026 confirment que les utilisateurs adoptent davantage un copilote quand ils comprennent pourquoi il fait une suggestion : l'explicabilité en langage simple renforce le sentiment de contrôle.
Intégrer le copilote là où l'utilisateur travaille déjà
Un copilote qui oblige à ouvrir un nouvel onglet ou à quitter son interface de travail est un copilote mort-né. L'IA doit s'intégrer nativement dans l'environnement existant : widget flottant, commande slash dans un éditeur, shortcut clavier, ou même intégration Slack pour les équipes qui vivent dans leur messagerie. Avec le protocole MCP, ces intégrations sont devenues beaucoup plus simples à implémenter : un serveur MCP unique permet au copilote de se connecter à l'ensemble des outils de l'utilisateur. GitHub Copilot illustre cette approche avec ses fichiers .agent.md qui permettent de définir des agents personnalisés directement dans un dépôt, avec accès complet au contexte du workspace et aux connexions MCP externes.
Pensez également à l'affordance : l'utilisateur doit comprendre immédiatement qu'il peut interagir avec le copilote. Un simple icône de chat ou un input prompt bien placé suffisent souvent. En revanche, un bouton perdu au fin fond d'un menu déroulant ne sera jamais utilisé, aussi puissant soit le copilote derrière.
Préserver le contrôle utilisateur
Un bon copilote assiste, il ne remplace pas. Les utilisateurs doivent toujours avoir le dernier mot. Si le copilote génère un email, laissez l'utilisateur l'éditer avant envoi. S'il crée une tâche, permettez de modifier l'assignation ou la deadline. Cette capacité de contrôle rassure et encourage l'adoption.
De même, soyez explicite sur ce que fait le copilote en arrière-plan. Si vous utilisez des données sensibles pour améliorer les réponses, informez-en l'utilisateur. Si le copilote apprend de ses interactions, offrez la possibilité de désactiver cet apprentissage. La récente mise à jour de la politique de confidentialité de GitHub Copilot (utilisation des données d'interaction pour l'entraînement par défaut depuis avril 2026) montre l'importance de ce sujet : les utilisateurs doivent savoir exactement ce qui est collecté et pouvoir s'y opposer. La confiance est la condition sine qua non de l'adoption d'un outil IA. En 2026, les utilisateurs attendent de savoir comment l'IA a pris sa décision, d'où viennent les données, et ce qui va se passer ensuite : la transparence algorithmique est devenue un critère de choix. Les frameworks de gouvernance entreprise (comme Agent 365 de Microsoft, disponible depuis le 1er mai 2026) intègrent désormais des scopes de permissions, des workflows d'approbation et des audit trails complets pour chaque action d'agent.

Construire un copilote IA qui délivre une vraie valeur demande une approche produit rigoureuse. Il ne s'agit pas de plaquer une intelligence artificielle sur un outil existant, mais de repenser profondément les workflows pour que l'IA devienne un prolongement naturel de l'utilisateur. Cela commence par identifier les vrais problèmes, passe par des choix d'architecture pragmatiques (RAG, agents, MCP, orchestration multi-agents, routage multi-modèles) qui servent ces problèmes, et se concrétise dans une expérience utilisateur fluide, transparente et respectueuse du contrôle utilisateur. Avec la baisse massive des coûts API et la maturité des protocoles comme MCP et A2A, les barrières techniques sont plus basses que jamais : l'enjeu principal reste la vision produit.
Chez Lonestone, nous accompagnons régulièrement des équipes dans cette démarche : de l'idéation des use cases à la mise en production d'un copilote scalable. Parce qu'au-delà de la technologie, c'est la vision produit qui fait la différence entre un gadget éphémère et un assistant IA qui transforme durablement la façon de travailler.
